

Un duel Le Pen – Fillon : le Big Data plus fiable que les sondages ?

Des Data Scientists de Télécom Paris Tech tentent de prédire les résultats du premier tour de la présidentielle via le Big Data, en associant historique des votes par département, sondages, Twitter et recherches Google.
Le Big Data peut-il se montrer plus fiable que les sondages quant il s’agit de prédire les résultats du premier tour d’une des présidentielles les plus incertaines de la 5ème République ? C’est le pari de 5 étudiants de l’école Télécom Paris Tech, associés au magazine Le Point. Ces étudiants (Mohamed Al Ani, Davy Bensoussan, Alexandre Brehelin, Bertrand de Véricourt et Raphaël Vignes) ont mis au point une méthode expérimentale, appelée Predict The President, qui tente d’affiner les études d’opinion via l’approche Big Data. Une méthode qui donne Marine Le Pen (avec plus de 24 %) et François Fillon (près de 22 %) vainqueurs du premier tour de dimanche prochain, devant Emmanuel Macron (plus de 20 %) et Jean-Luc Mélenchon (près de 19 %). Benoit Hamon serait, lui, largement distancé (à peine plus de 5 %).
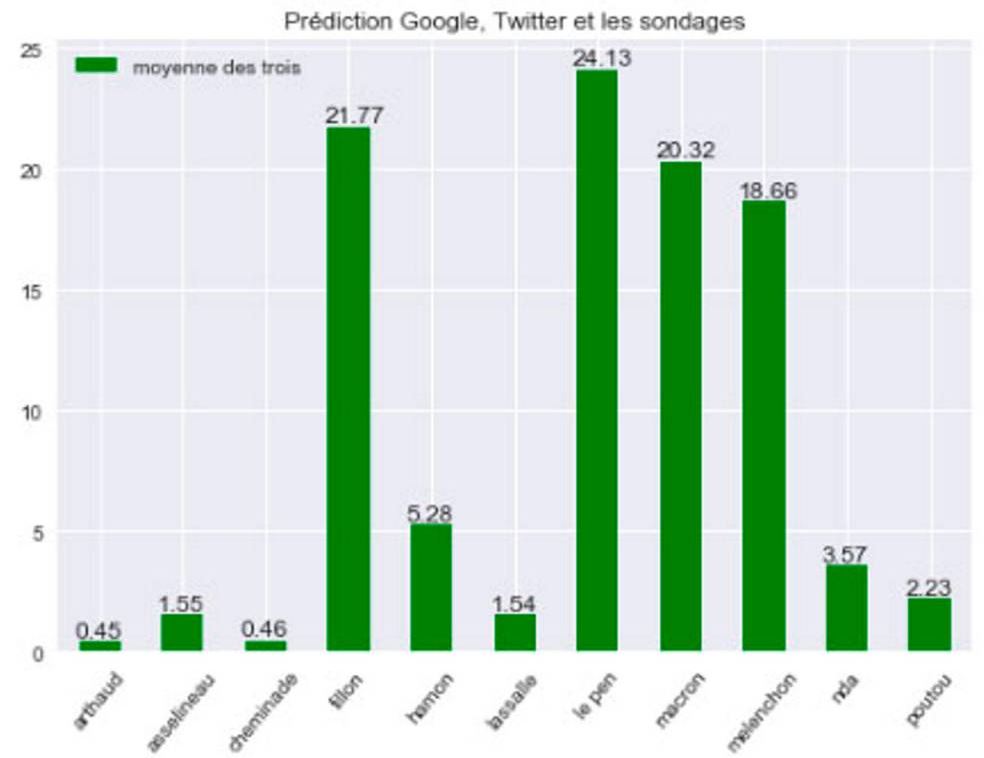 Pour parvenir à ce résultat qui tranche avec des sondages qui donnent plutôt l’avantage à Emmanuel Macron et Marine Le Pen, les étudiants combinent les études d’opinion, les données socio-démographiques et économiques depuis 1981 et une analyse des tendances sur Twitter et sur le moteur de recherche de Google. Dans le modèle mis en place, l’historique des votes par départements, des données disponibles en Open Data, joue un rôle clef et vient nourrir le modèle. A partir de quelques hypothèses de base. Primo, les étudiants scindent les votes en 4 catégories : le bloc de gauche (regroupant PS et extrême gauche « pour des raisons de performances du modèle », indiquent les Data Scientists), le bloc du centre, le bloc de la droite et le bloc de l’extrême droite. Second parti pris : Emmanuel Macron appartient au bloc de gauche. Enfin, les étudiants de Télécom Paris Tech affirment que le vote départemental peut être expliqué par des données sociales, démographiques et économiques qui pèseront également en 2017. Là encore une masse d’informations récupérées via l’Open Data. Des hypothèses qui peuvent évidemment être discutées (en particulier l’appartenance du candidat d’En Marche au bloc de gauche).
Pour parvenir à ce résultat qui tranche avec des sondages qui donnent plutôt l’avantage à Emmanuel Macron et Marine Le Pen, les étudiants combinent les études d’opinion, les données socio-démographiques et économiques depuis 1981 et une analyse des tendances sur Twitter et sur le moteur de recherche de Google. Dans le modèle mis en place, l’historique des votes par départements, des données disponibles en Open Data, joue un rôle clef et vient nourrir le modèle. A partir de quelques hypothèses de base. Primo, les étudiants scindent les votes en 4 catégories : le bloc de gauche (regroupant PS et extrême gauche « pour des raisons de performances du modèle », indiquent les Data Scientists), le bloc du centre, le bloc de la droite et le bloc de l’extrême droite. Second parti pris : Emmanuel Macron appartient au bloc de gauche. Enfin, les étudiants de Télécom Paris Tech affirment que le vote départemental peut être expliqué par des données sociales, démographiques et économiques qui pèseront également en 2017. Là encore une masse d’informations récupérées via l’Open Data. Des hypothèses qui peuvent évidemment être discutées (en particulier l’appartenance du candidat d’En Marche au bloc de gauche).
Google : un indicateur donnant Trump vainqueur
Sur la base de ces hypothèses, et d’une analyse département par département, les algorithmes permettent d’attribuer un pourcentage de vote à chaque bloc, avec une marge d’erreur de 2,5 % si on se réfère à l’élection de 2012. La seconde étape du travail des étudiants consiste à tenter de mesurer l’influence de la personnalité des candidats sur ces grands équilibres. En injectant les données des sondages, celles de Twitter et les recherches sur Google. Sur le réseau social, les étudiants ont collecté des tweets publiés entre les 10 et 15 avril, sur lesquels ils ont appliqué une analyse de sentiment, pour mesurer l’opinion des twittos vis-à-vis de chaque candidat. Un segment où François Fillon, très populaire sur le réseau social malgré le #PenelopeGate, fait jeu égal avec Marine Le Pen.
Mais, pour les Data Scientists de Télécom Paris Tech, école qui a lancé un mastère spécialisé en Big Data, l’analyse du très politisé réseau Twitter ne saurait suffire. Les étudiants notent ainsi que « l’un des rares indicateurs à avoir prédit la victoire de Donald Trump était bien Google », l’actuel président des États-Unis y bénéficiant d’un bien plus grand nombre de recherches que sa concurrente, Hillary Clinton. Sur ce terrain, ce sont cette fois Marine Le Pen et Jean-Luc Mélenchon qui se détachent.
Des variables et des hypothèses
C’est en combinant les trois approches que les étudiants parviennent à leur duel entre le candidat LR et la présidente du Front National. « L’algorithme que nous avons construit pour prédire les résultats des blocs est certes performant pour 2012, mais il ne se base que sur les variables que nous avons construites et des hypothèses que nous avons prises », avertissent toutefois les Data Scientists. Ceux-ci notent ainsi que l’écart entre le second – François Fillon, selon leur modèle – et le troisième –Emmanuel Macron – reste dans la marge d’erreur. « Tous nos modèles de pondération donnent cependant Marine Le Pen au second tour », notent toutefois Mohamed Al Ani et Raphaël Vignes, deux des étudiants de Télécom Paris Tech dans les colonnes du Point.
A lire aussi :
Open Data : le service public de la donnée ouvre ses portes
Numérique et Présidentielle, un débat hélas sans candidats
François Hollande veut protéger la présidentielle des cyberattaques






