

LinkedIn place en Open Source son outil Big Data, WhereHows

Pour disposer d’une vue unifiée de ses silos de données, LinkedIn a bâti un entrepôt de métadonnées couplé à des outils de découverte. Une solution baptisée WhereHows que la société américaine confie à la communauté Open Source, dans l’espoir d’accélérer les développements.
Après Google, Netflix ou Yahoo, un autre grand du Web, LinkedIn, mise sur la communauté Open Source pour l’aider à améliorer un outil maison, en l’occurrence ici sa solution de datamining WhereHows. Ce projet de l’équipe LinkedIn Data, désormais disponible sur GitHub, « fonctionne en créant un entrepôt de données central et un portail pour les processus, les personnes et les connaissances autour de l’élément le plus important de tout système Big Data : les données elles-mêmes », résume Eric Sun, un ingénieur du réseau social professionnel (le deuxième en partant de la droite sur la photo ci-dessus montrant l’équipe du projet). En l’état actuel, l’entrepôt maison agrège les métadonnées de 50 000 jeux de données (soit plus de 15 Po répartis au travers de différents clusters, dont des clusters Hadoop ou Teradata), mais aussi celles de 14 000 commentaires ou de 35 millions d’opérations sur les données et d’éléments concernant la lignée des données.
Comme l’explique Eric Sun dans un billet de blog, la solution vise à unifier la grande diversité des environnements Big Data que LinkedIn a accumulé au fil du temps. « Nous avons différentes sources et bassins de données. Nous écrivons des flux de production pilotés par différents moteurs d’ordonnancement et nous supportons de nombreux moteurs de transformation différents utilisés pour traiter et créer des données dérivées, décrit l’ingénieur. Cette forme de spécialisation est intéressante car elle nous donne accès au meilleur outil pour chaque tâche ; elle crée néanmoins une nouvelle série de problèmes. » C’est cette difficulté à donner du sens au flux de données global qui a donné naissance à WhereHows, afin d’améliorer la productivité d’employés perdus dans de multiples silos d’informations et de dénicher de nouvelles corrélations.
Les multiples sources de données de LinkedIn
Après avoir mis en place une équipe chargée de construire un datawarehouse regroupant les données essentielles des différents silos, LinkedIn s’est lancé dans la construction d’un entrepôt de métadonnées, WhereHows, afin de « simplifier les problèmes de découverte de données et de flux ». Un travail de longue haleine qu’Eric Sun juge loin d’être achevé. Mais le passage en Open Source devrait aider à accélérer les développements, espère LinkedIn. Pour l’heure, l’entrepôt est accessible via une application Web et via une API. Le portail offre des outils de navigation, de recherche et de visualisation des liens de parenté associés à des fonctions communautaires (permettant des annotations par exemple).
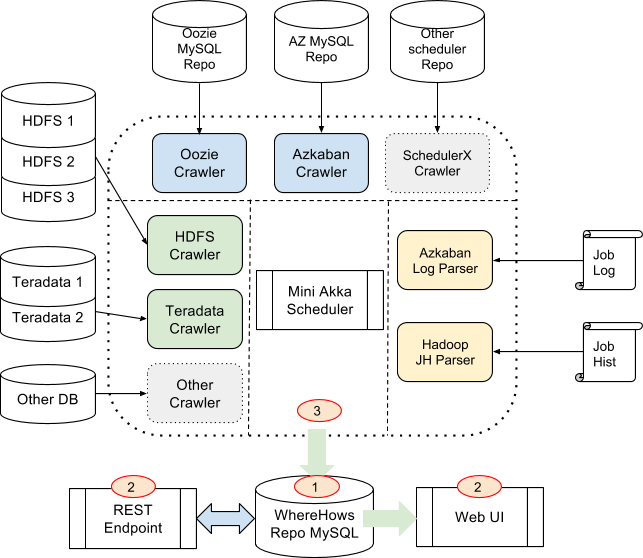
Mais, comme l’explique Eric Sun, la clef de la technologie réside dans deux éléments clefs. L’intégration des données de différentes sources (Hadoop, Hive ou Teradata) dans un « modèle universel » d’abord. C’est ce qui permet à l’outil, par exemple, d’effectuer une recherche à travers l’ensemble de l’environnement. L’information de parenté ensuite. « Le pont permettant de connecter » les métadonnées des jeux de données et celles relatives aux traitements, selon l’ingénieur.
A lire aussi :
Google veut faire de Dataflow un projet incubateur Apache
La Poste Courrier préposée à transformer le Big Data en or
Cédric Villani, « Plus il y aura d’IA, plus il y aura besoin des mathématiciens »






