

Dreamforce 14 : Wave fait déferler l’analytique sur Salesforce1

Deux semaines après Oracle, Salesforce annonce son Analytics Cloud baptisé Wave. Une forte attente de ses utilisateurs, mais une plate-forme analytique basique face à celles du marché. Une belle première approche qui ne demande qu’à grandir.
Pour répondre à un reproche des utilisateurs de ses clouds sur les fonctions analytiques limitées à du reporting (malgré que cette tâche reste la plus utilisée dans les entreprises), Salesforce lance son cloud Wave apportantà l’entreprise des fonctions analytiques évoluées avec des capacités d’auto-découverte, exploratoires, ergonomiques et à la portée de tous.
Certes, Marc Benioff, fondateur et dirigeant de Salesforce, tente de présenter ce lancement de Wave comme « une entrée fracassante sur le marché de l’analytique, tout comme nous avons bouleversé le marché du CRM il y a 15 ans.» Néanmoins, il s’agit essentiellement pour Salesforce de remettre ses clouds au niveau de solutions existantes et très plébiscitées, dans le sillon de pionniers comme Qlik, Spotfire (détenu par Tibco) ou Tableau. Et, au passage, de répondre à l’annonce faite il y a 2 semaines par Oracle avec son Oracle Analytics Cloud à San Francisco. Heureux hasard.
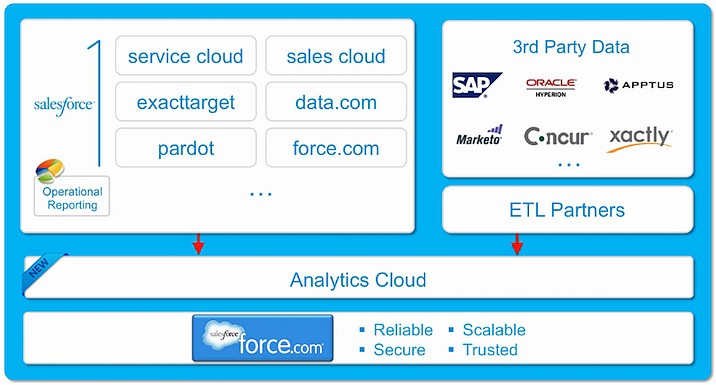
Un cloud pour trois scénarios
Contrairement à la solution de conception d’applications mobiles Lightning relatée hier, Wave n’est pas une brique de la plateforme, mais bien un cloud à part entière, qui sera également proposé dès le 20 octobre (en anglais et sous iOS dans un premier temps) pour une utilisation possible indépendamment de la plateforme Salesforce1.
Bien entendu, l’intégration native à Salesforce1 est assurée, favorisant le travail sur les données des clouds de Salesforce et le partage des fonctionnalités d’identification, de sécurité et de conformité des données.
Premier scénario : l’administrateur de bases de données Salesforce fait simplement glisser les données des clouds ou de la plateforme Salesforce, y compris issues d’applications de partenaires conçues sur la plateforme dans Wave pour les rendre accessibles sur ce cloud. Dans ce cas, les schémas de données et leurs liens sont connus puisque ces données sont sur Salesforce.
Second scénario : administrateurs ou développeurs se servent des API de Wave, de connecteurs de données ou d’ETL tiers (comme Informatica) pour accéder à des données ou informations non structurées (SAP, Oracle, etc.) et les intégrer dans Wave.
Troisième scénario : une feuille Excel peut être utilisée comme source directement dans Wave qui propose alors une fonction de mapping (suffisante) pour organiser ces données.
Toutes ces opérations et quelques autres (même si pour le moment, Wave ne se positionne pas sur l’ETL) sont réalisées via le service Wave Builder qui permet de créer, déployer et gérer des datasets (jeux de données), des connexions et des accès aux données. Avec ce service, l’utilisateur peut très simplement créer et distribuer des applications analytiques ou tableaux de bord mixant diverses sources (pour navigateur sur périphériques fixes ou mobiles), définir des droits d’accès, etc. Le prix est fixé à 250 dollars par mois et par utilisateur (avec engagement minimum d’un an).
A noter : il est possible de réaliser quelques opérations (basiques) de type transformation.
Que se passe-t-il alors ? « Wave organise de façon automatisée les informations qui lui sont “poussées” en fichiers plats en étoile, représentant autant de dimensions,» explique un expert de Salesforce. « Ensuite, un traitement de type “No SQL Olap” (expression correspondant à peu près aux opérations effectuées) est réalisé sur ces informations qui peuvent alors être manipulées, explorées, etc.» Outre ce pseudo-cube de type multidimensionnel, Salesforce précise que Wave travaille en mode massivement parallèle.

Une interface ergonomique et collaborative
L’interface d’exploration des données est permise par l’accès au service Wave Explorer pour 250 dollars par mois et par utilisateur (avec engagement minimum d’un an). Au menu : visualisations diverses et explorations illimitées, découverte d’information, personnalisation, accès à toutes les applications analytiques (conçues sous Wave Builder), fonctions zoom et drill, etc. Autre dimension intéressante, la collaboration avec la possibilité de partager des graphiques et tableaux de bord, d’enregistrer des visualisations ou des résultats, de discuter en ligne sur les données, de partager et d’annoter, etc.
Pas de substitution des fonctions de reporting
On pourrait s’interroger sur le devenir des fonctions analytiques existantes. « Ces fonctions disponibles sur notre plate-forme sont maintenues et continuent à évoluer. Elles remplissent un rôle spécifique de reporting très demandé également par nos utilisateurs,» assure Jean-Louis Baffier, vice-président EMEA chez Salesforce.
Une des tendances fortes de ces applications exploratoires très visuelles consiste à intégrer la mise à jour des données sources via ces interfaces. « Le cloud Wave est tout juste annoncé, mais va très vite évoluer et s’enrichir,» affirme Jean-Louis Baffier. « Toutefois, il est déjà possible depuis Wave Explorer de faire appel à la fonction de mise à jour de données, à condition qu’elles proviennent de notre plate-forme. Cependant, ce type de fonction devrait rapidement s’étendre.»
Pas de Big Data en dessert
Bien que Salesforce surfe sur les technologies tendance et porteuses, elle reste très discrète sur Big data à propos de Wave. D’ailleurs Hadoop (semblant faire l’unanimité auprès des acteurs de l’analytique) n’est pas encore proposé et ne sera peut-être pas compatible avec la technologie utilisée.
« Si vous souhaitez analyser quelques gigaoctets, éventuellement un ou deux téraoctets, sur Wave, pas de problème,» pouvait-on entendre dans les allées. « Cependant, au-delà, Salesforce demande de patienter encore quelque temps.» D’autant plus qu’il s’agit à chaque fois de recopier un volume de données conséquent. Et même avec des algorithmes d’optimisation et du massivement parallèle, l’exercice peut vite devenir délicat face à de très grands volumes, et certainement plus onéreux.
A lire aussi :






