Word Cloud "Big Data"
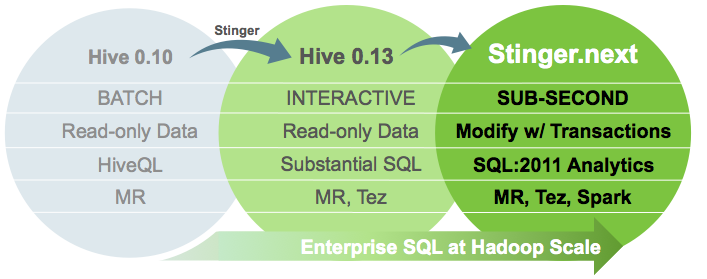
Depuis le mois d’avril dernier, des équipes de Hortonworks ont travaillé avec la communauté Open Source Hive (soit plus de 140 développeurs) pour préparer le futur de ce logiciel d’analyse de données permettant d’utiliser Hadoop avec une syntaxe proche du SQL. L’objectif de cette initiative, baptisée Stinger.next, est d’être capable de gérer les transactions en temps réel, de prendre en charge l’ensemble de la sémantique SQL et d’afficher des résultats d’une requête en moins d’une seconde.
Pour réaliser cela, le projet a réuni plus de 390 000 lignes de code et a bénéficié du soutien de 44 entreprises qui ont fourni des ingénieurs spécialisés dans l’analytique et les datas, un moteur puissant de requêtes SQL, ainsi qu’un jeu de données à l’échelle du Po. Comme le soulignent nos confrères de GigaOM, c’est la seconde fois que Hortonworks mène un projet pour optimiser Hive. Des travaux avaient eu lieu en 2012, sous le nom Stinger. Ils avaient permis, selon l’éditeur, d’améliorer par un facteur 100 les performances du moteur.
Stinger.next s’inscrit donc dans la continuité de ces travaux et un billet de blog donne les grandes orientations de cette initiative et la roadmap de ces efforts avec la communauté Hadoop. Sur l’échéancier, on distingue 3 phases (comme le montre l’image ci-dessous). Primo, le support des transactions ACID (atomicité, cohérence, isolation et durabilité), attendu d’ici à la fin de cette année. Secundo, au début de l’année prochaine, le projet devrait atteindre l’objectif du temps réel et l’intégration de Spark. Tertio, vers la fin 2105, Stinger.next accueillera des requêtes SQL complètes.
Si le succès est au rendez-vous pour Stinger.next, cela pourrait impacter d’autres fournisseurs qui ont fait le pari de construire leur propre moteur SQL basé sur d’autres technologies que Hive. On peut citer, par exemple, Impala de Cloudera, Big SQL chez IBM, Greenplum pour Pivotal. D’autres projets Open Source sont en cours de développement comme Presto chez Facebook, Apache Phoenix pour Salesforce.com et Apache Drill chez MapR. La communauté Spark travaille également sur des moteurs interactifs avec SparkDB et BlinkDB.
A lire aussi :
Pivotal et Hortonworks s’associent dans la gestion de Hadoop
Apache vient booster Hadoop avec Spark 1.0
Après avoir essaimé dans 145 pays, la communauté de femmes de la tech Women Who…
Les voix du CISPE et des associations d'utilisateurs s'accordent face à Broadcom et à ses…
Bonnes pratiques, indicateurs, prestataires... Aperçu de quelques arbitrages que le comité d'organisation de Paris 2024…
Le 31 mars 2023, le PTCC (Programme de transfert au Campus Cyber) était officiellement lancé.…
Nicolas Gour, DSI du groupe Worldline, explique comment l’opérateur de paiement fait évoluer sa gouvernance…
Comme avant la Coupe du monde de rugby, l'ANSSI dresse un état des lieux de…
{kind=link}