

Une loi de Moore pour l’IA ?

Le progrès algorithmique dans le domaine de l’IA peut-il se résumer sous la forme d’une « loi de Moore » ? Les travaux d’OpenAI alimentent la réflexion.
Existe-t-il, dans le domaine de l’IA, un équivalent à la loi de Moore ? Les travaux d’OpenAI alimentent la réflexion.
L’association, devenue l’an passé entreprise à « but lucratif plafonné », a cerné trois facteurs principaux de développement de l’intelligence artificielle : les données, les ressources de calcul et l’innovation algorithmique.
Elle s’est intéressée à ce dernier, sous un aspect en particulier : l’« efficacité algorithmique ».
Traditionnellement, cette métrique rend compte de la réduction de la puissance de calcul nécessaire pour atteindre une capacité spécifique.
Pour mieux coller à l’apprentissage automatique, où la difficulté des tâches est plus complexe à évaluer, OpenAI a travaillé à performance de calcul constante. Ses démarches se sont limitées à la phase d’entraînement des modèles.
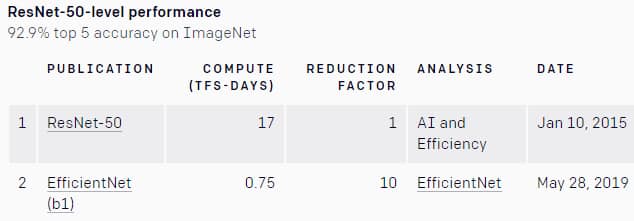
Principal objet de l’étude : la classification d’images, à partir de la base ImageNet.
Constat : entre 2012 et 2020, la puissance de calcul requise pour atteindre un même niveau d’entraînement a été divisée par deux tous les 16 mois.
Cette valeur se fonde sur le différentiel mesuré entre EfficientNet et AlexNet. Le premier nécessite 44 fois moins de ressources pour arriver au même niveau que le second à l’époque*.


Toujours dans la classification d’images, OpenAI a observé une évolution similaire avec ResNet-50 : puissance requise divisée par deux tous les 17 mois.
Les résultats sont comparables pour la phase d’inférence : doublement tous les 15 mois entre AlexNet et Shufflenet ; tous les 13 mois entre ResNet et EfficientNet.
Jeux et traduction
En s’appuyant essentiellement sur des réimplémentations open source (PyTorch notamment), OpenAI a élargi son analyse à d’autres types de tâches. Entre autres, la traduction.
Les progrès y sont nettement plus rapides que pour les tâches liées à la vision.
Illustration avec Transformer, qui a nécessité 61 fois moins de ressources que Seq2Seq pour traduire un texte anglais en français, sur la base du WMT14.

Même tendance dans le domaine des jeux, avec des mesures toutefois faites à plus faible intervalle.

OpenAI perçoit plusieurs explications à ces progrès. Parmi elles, la normalisation des lots, l’exploitation des connexions résiduelles et la capacité à généraliser à partir de faibles échantillons de données.
En toile de fond, un appel aux parties prenantes du développement de l’IA (chercheurs, économistes, régulateurs…) afin qu’ils intègrent davantage, dans leurs arbitrages, la notion de progrès algorithmique, à court comme à long terme.
Dans cet esprit, OpenAI annonce la publication prochaine d’une première série de benchmarks. Et encourage la communauté à lui en transmettre.
* Il y a des limites à la démonstration, reconnaît OpenAI. Mais dans les deux sens.
D’un côté, l’analyse n’a pas tenu compte des éventuels gains liés à la possibilité d’utiliser du calcul à faible précision ou d’utiliser des noyaux GPU optimisés.
De l’autre, AlexNet a été à l’origine entraîné sur 90 cycles. Or, 62 lui suffisent pour atteindre 99,6 % de sa performance finale.
Illustration principale © Natalia Shepeleva – Shutterstock.com






