

Machine learning : IBM pousse ModelMesh de Watson à Kubeflow

Le projet KServe (composante de Kubeflow) accueille ModelMesh, un gestionnaire de modèles qu’IBM utilise sur son offre Watson.
Version mineure, changements majeurs ? Ça bouge en tout cas du côté de KFServing. Ou plutôt de KServe. Telle est la nouvelle marque associée à ce projet né voilà deux ans* dans le cadre de l’initiative Kubeflow (« boîte à outils » pour le machine learning sur Kubernetes), dont il constitue la brique « déploiement ».
Ce rebranding s’accompagne d’un nouveau dépôt GitHub indépendant. Kubeflow en reste le coordinateur, mais une sortie de son giron est prévue d’ici à la fin de l’année.
Du changement, il y en a aussi en back-end. Avec la version 0.7.0, fraîchement lancée, KServe adopte ModelMesh. « En substance, il fonctionne comme un cache LRU distribué », résume IBM.
Le groupe américain est à l’origine de cette couche logicielle destinée à optimiser l’un des aspects du processus d’inférence : la mise à disposition des modèles. Il l’utilise sur plusieurs composantes de l’offre Watson (Assistant, NLU, Discovery). La voilà désormais en open source, intégrée au projet KServe.
Moins de serveurs, plus de modèles
Cible de ModelMesh : les applications qui font appel à de nombreux modèles. Par exemple, un par utilisateur pour des questions de privacy. Ou un par catégorie lorsqu’il s’agit de classer des éléments. La promesse : dépasser le paradigme « un modèle, un serveur », dont la mise en œuvre sur Kubernetes présente des complexités. Entre autres :
– Utilisation des ressources de calcul, notamment de par les sidecars injectés dans chaque pod
– Limite de pods par nœud
Par défaut, cette valeur est à 110. Pour un cluster à 50 nœuds, cela veut dire qu’on peut exécuter au mieux 1000 modèles, en partant du principe que chacun va utiliser en moyenne 4 pods (2 répliques transformatrices, 2 répliques prédictrices).
– Plafond d’IP
Chaque pod dans un serveur d’inférence a besoin d’une adresse. Sur la base sus-évoquée, un cluster à 4096 IP peut accueillir au mieux 1024 modèles.
ModelMesh permet d’exploiter des serveurs multimodèles. Il orchestre leur disponibilité sur le principe du LRU (least recently used = remplacement de celui utilisé le moins récemment), via un point de terminaison gRPC (proxy REST disponible). Il équilibre aussi les requêtes d’inférence entre toutes les copies d’un modèle.

On nous promet, avec le couple KServe + ModelMesh, une capacité d’exécution de « centaines de milliers » de modèles dans un environnement de 8 pods.
* Bloomberg, Google, IBM, NVIDIA et Seldon sont impliqués dans le développement de KServe. Leur objectif : fournir un protocole d’inférence standardisé entre frameworks.
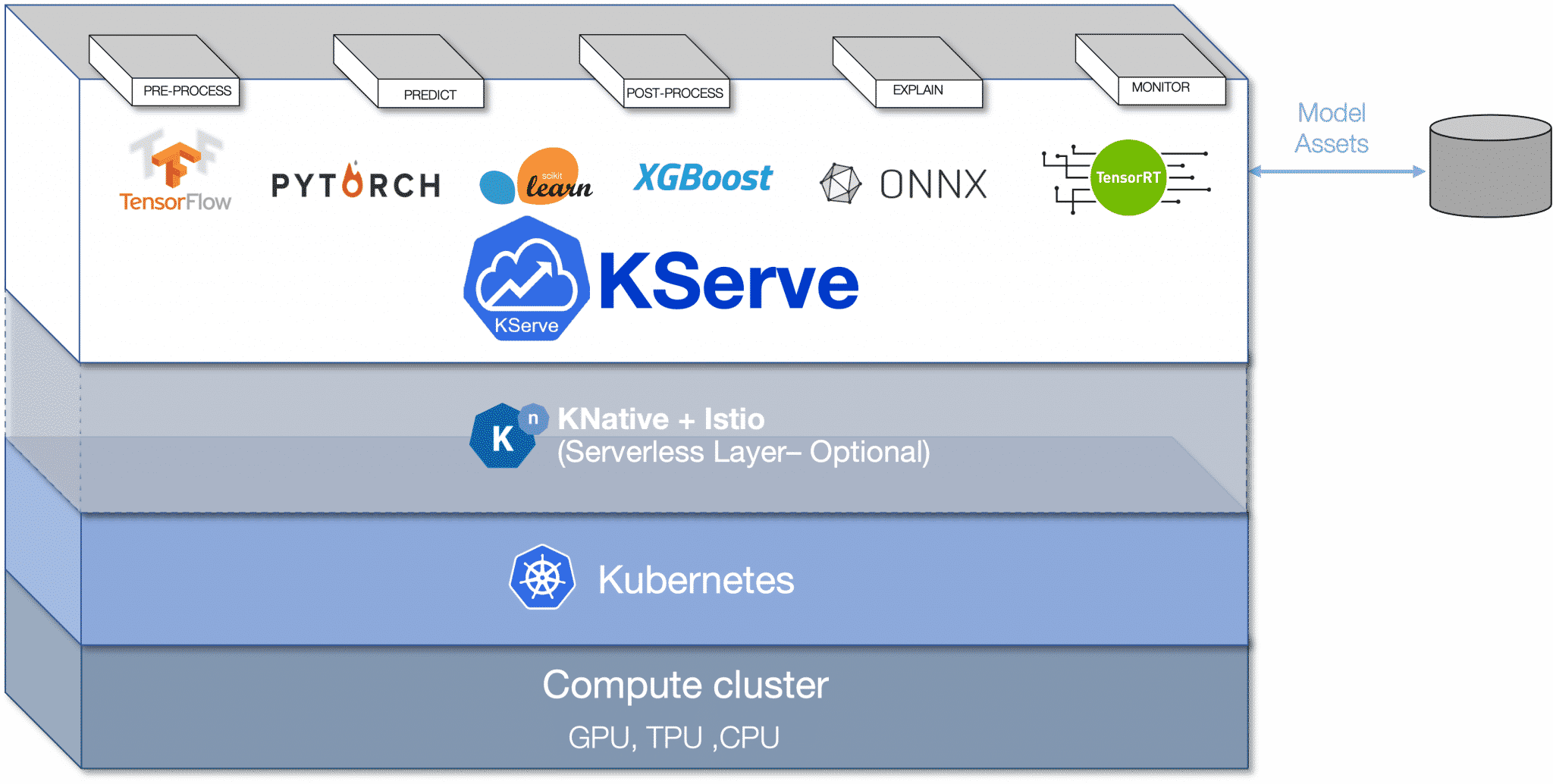
Illustration principale © Siarhei – Adobe Stock






