

OpenAI : que peut-on faire avec l’API ?

Voilà un peu plus d’un an que l’API d’OpenAI est ouverte sans liste d’attente. À quoi donne-t-elle accès ?
À quelles fonctionnalités l’API d’OpenAI donne-t-elle accès et comment les mettre en œuvre ? Nous avions fait, début 2022, un petit tour du propriétaire.
Depuis lors, le périmètre fonctionnel a évolué. La structure et les points d’entrée de l’API ont changé ; comme, dans une moindre mesure, la terminologie. Par exemple pour la catégorisation des modèles sous-jacents : le concept de moteurs a laissé place à celui de familles.
Ces dernières restent au nombre de trois :
– GPT-3 (traitement et production de langage naturel)
– Codex (analyse et production de code informatique)
– Content filter (détermination du niveau de sensibilité d’un texte)
La famille GPT-3 regroupe toujours quatre modèles, sous les mêmes noms qu’à l’origine. Et sur le même principe : à mesure qu’on progresse dans l’ordre alphabétique, ils deviennent plus performants. Mais aussi plus chers.
OpenAI conseille d’expérimenter avec Davinci et de redescendre au fur et à mesure vers le bon compromis. En gardant à l’esprit ces correspondances tâches-modèle :
– Davinci : résumé thématique, création de contenu, détection de relation cause à effet
– Curie : traduction, analyse de sentiment, résumé et Q&A génériques
– Babbage : classification simple, recherche sémantique
– Ada : détection de mots-clés, correction d’adresses…

Les modèles GPT-3 s’utilisent avec le point de terminaison /completions. On peut aujourd’hui lui soumettre des tâches auparavant dévolues à d’autres endpoints : /classifications, /search (recherche sémantique) et /answers (Q&A).
Depuis notre premier tour d’horizon, deux options expérimentales sont venues étendre /completions. L’une permet, avec Davinci, d’insérer les réponses dans l’énoncé d’origine. L’autre, d’éditer ce même énoncé. Elle utilise un modèle spécifique (text-davinci-edit-001).


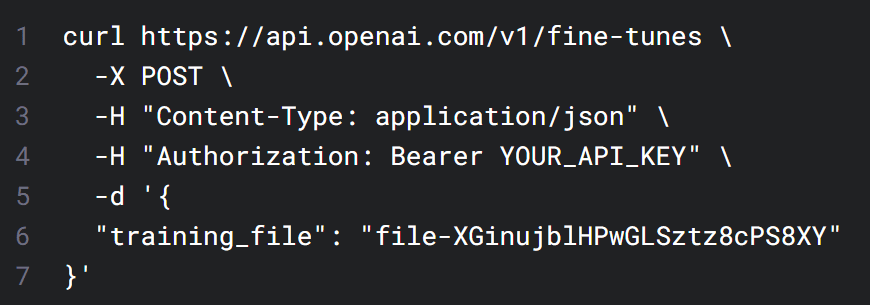
Les anciennes versions d’Ada, Babbage, Curie et Davinci restent disponibles. De préférence, pas pour les utiliser telles quelles, mais pour les affiner. Ce avec le point de terminaison /fine-tunes, en ayant éventuellement téléversé au préalable des données d’entraînement (/files). Par défaut, c’est Curie qu’on affine. Un outil en ligne de commande peut aider à valider et à reformater le dataset.
Un nouvel endpoint pour la modération
L’option insertion fonctionne également avec Codex. Idem pour l’option édition – qui, là aussi, utilise un modèle spécifique : code-davinci-edit-001.
La famille Codex préfère toujours Python, même si elle gère une dizaine de langages (Go, JavaScript, PHP, Ruby, Swift, TypeScript…). Les recommandations générales d’il y a un an sont toujours d’actualité : spécifier quelles bibliothèques utiliser, insérer les commentaires dans des fonctions, etc.

Content filter existe toujours. Avec le même rôle qu’à l’origine : estimer la « sensibilité » des résultats que produisent les modèles GPT-3 et Codex. Le point de terminaison recommandé a toutefois changé : place à /moderation. Deux modèles sont à disposition, selon qu’on souhaite disposer du plus récent (text-moderation-latest) ou de la dernière version stable (text-moderation-stable).
Autre point de terminaison, autre fonction : /embeddings permet de créer des représentations vectorielles de chaînes de caractères. D’autres modèles pourront ensuite les exploiter pour évaluer la proximité entre ces chaînes. Par exemple dans le cadre de moteurs de recherche, de systèmes de recommandation ou d’outils de détection d’anomalies.
Avec /embeddings, on peut utiliser pas moins de 16 modèles de première génération… et un de deuxième génération (celui par défaut : text-embedding-ada-002).
DALL-E est arrivé
Le « gros » ajout de 2022, c’est l’API DALL-E. En bêta publique depuis novembre, elle comporte trois options : créer des images(/image-generations), en éditer (/image-edits) ou en faire des variations (/image-variations).
La première option génère, à partir d’une requête de 1000 caractères maximum, des images carrées de 256, 512 ou 1024 pixels de côté. Par défaut, une à la fois, mais on peut pousser jusqu’à dix. Deux formats de sortie sont possibles : soit en Base64, soit sous forme d’une URL qui reste valide une heure.
L’option « édition » implique d’uploader à la fois une image et un masque. En fait une deuxième image, de mêmes dimensions, et dont les parties transparentes correspondent à celles qui seront éditées. Image et masque doivent être en PNG, dans un format carré et peser moins de 4 Mo. La limite pour la consigne textuelle est la même : 1000 caractères.
La troisième option utilise les mêmes paramètres, sans masque.
Quatre cycles d’entraînement par défaut
Il y a toujours deux canaux made in OpenAI pour accéder à l’API : des bindings Python et une bibliothèque Node.js. Les autres proviennent d’initiatives communautaires, englobant une dizaine de plates-formes de C#/.NET à Unreal Engine.
L’unité de facturation est toujours le token. Il équivaut à un « morceau de mot » : environ 4 caractères. OpenAI propose un outil en ligne pour vérifier le poids d’une requêtes.
La tarification des modèles de base sur /completions tient compte du nombre de tokens en entrée et en sortie.

L’entraînement de modèles (par défaut, sur quatre cycles) puis leur usage font l’objet de tarifications différenciées.

DALL-E ne fonctionne pas par token, mais pas image.

Pour des précisions sur les possibilités de paramétrage des modèles, voir, ci-dessous, le point effectué début 2022.
L’API OpenAI début 2022
Moteurs, modèles, points de terminaison… Pas si facile de s’y retrouver dans l’offre commerciale d’OpenAI, tant elle a pris du volume depuis son lancement à la mi-2020.
Il n’y a pas si longtemps (novembre 2021) que l’API est accessible sans liste d’attente. Les modèles sous-jacents sont catégorisés en trois moteurs :
– GPT-3 (traitement et production de langage naturel)
– Codex (analyse et production de code informatique)
– Content filter (détermination du niveau de sensibilité d’un texte)
Dans la catégorie GPT-3 se trouvent quatre modèles : Ada, Babbage, Curie et Davinci. Leurs anciennes versions – réunies sous la bannière Instruct – restent accessible. Tous acceptent du texte en entrée et produisent du texte en sortie.
À mesure qu’on progresse dans l’ordre alphabétique, les modèles deviennent plus performants : ils ont besoin de moins d’instructions pour en faire autant que ceux qui les précède. Mais ils coûtent aussi plus cher à utiliser. Et peuvent induire des traitements plus longs.
De manière générale, OpenAI conseille d’expérimenter avec Davinci et de redescendre au fur et à mesure vers le bon compromis. En gardant à l’esprit ces correspondances tâches-modèle :
– Davinci : résumé thématique, création de contenu, détection de relation cause à effet
– Curie : traduction, analyse de sentiment, résumé et Q&A génériques
– Babbage : classification simple, recherche sémantique
– Ada : détection de mots-clés, correction d’adresses…
Un outil permet de comparer les modèles GPT-3 côte à côte. Et de télécharger les résultats (.xls).

Codex préfère Python
Dans la famille Codex, deux modèles également 100 % texte, descendants des premiers GPT-3 :
– Davinci
Acceptant jusqu’à 4096 tokens par requête, il est idéal pour la traduction de langage naturel en code.
– Cushman
Avec jusqu’à 2048 tokens/requête, il conviendra mieux aux applications temps réel.
Fonctionnent sur une dizaine de langages, ils « préfèrent » tous deux Python.
Que sont, au juste, les tokens ? C’est l’unité d’inférence de base d’OpenAI. Dans les grandes lignes, le texte, en entrée comme en sortie, est divisé de sorte que 4 caractères = 1 token. C’est aussi l’unité de facturation.
Le troisième moteur (Content filter) se compose pour le moment d’un seul modèle. On lui fournit du contenu qu’il classe comme sûr, sensible ou inapproprié. Plusieurs options permettent d’ajuster sa rigueur, dont la définition d’un seuil de certitude plancher.
Content filter a du mal avec certains styles de texte (fiction, code, poésie…) et certains formats (sauts de lignes fréquents, répétitions de mots…). Par ailleurs, comme pour tous les autres modèles, sa base de connaissances s’arrête à 2019. Un mécanisme d’entraînement continu est en travaux chez OpenAI.
Une IA de niveau collège ?
Pour utiliser Content filter, il faut passer par le point de terminaison de référence : /completions. Il en existe trois autres, destinés respectivement à la classification, à la recherche sémantique et au Q&A.
Deux canaux officiels pour joindre ces endpoints HTTP : des bibliothèques Python et Node.js. La communauté en a développé d’autres (C#/.NET, Crystal, Dart, Go, Java, PHP, Ruby, Unity, Unreal Engine).
On fournit aux modèles des instructions et si possible du contexte. Tout en paramétrant éventuellement certains éléments. Par exemple, la « température » : plus elle proche de 0, plus le modèle est déterministe ; plus elle est proche de 1, plus il prend des risques.
Par défaut, avec /completions, l’API est stochastique (elle produit des résultats différents à chaque appel). Dans l’idée, il faut lui parler comme on parlerait à un collégien. À la clé, de nombreux usages potentiels : classification, production de discours, transformation (résumé, traduction, reformulation de concepts…), réponses factuelles… et sollicitation de Codex.
Ce dernier peut aussi bien transformer des consignes en code qu’ajouter des commentaires, compléter une ligne ou suggérer un élément utile (bibliothèque, appel API…). OpenAI donne quelques conseils parmi lesquels :
– Préciser le langage utilisé et sa version
– Styliser les commentaires en fonction du langage
Avec Python, par exemple, Codex gère mieux la méthode non conventionnelle des triples guillemets que celle du dièse.
– Préférer le flux au batch pour améliorer la latence
Un goût d’autoML
En bêta, /classifications s’apparente à un autoML. On lui fournit des exemples étiquetés, soit à la volée (maximum 200), soit au travers de fichiers préchargés (maximum 150 Mo par fichier et 1 Go au total). Sans nécessiter d’entraînement ad hoc, il retourne les exemples les plus pertinents pour une requête donnée – après filtrage préalable des exemples par scoring sémantique.

On retrouve ce mécanisme de scoring sémantique a priori sur le point de terminaison /search. Avec les mêmes possibilités – et les mêmes limites de taille de fichiers – pour fournir des exemples. Et le même format en entrée : du JSON en lignes. Le résultat : un score de 0 à 300. Plus il est élevé, plus un texte et une requête se correspondent sémantiquement.

Le point de terminaison /answers a un fonctionnement comparable. Sauf qu’il évalue la pertinence par rapport à des questions.

OpenAI : des modèles aussi à entraîner
Plutôt que de leur fournir à chaque fois des exemples, on peut entraîner les modèles d’OpenAI avec des jeux de données personnalisés. La facturation est aussi fonction des tokens utilisés (nombre de tokens dans les fichiers d’entraînement x nombre de cycles).
On est là aussi sur du JSON en lignes, avec des paires requête-réponse. OpenAI propose un outil de ligne de commande pour aider à préparer les données à partir d’autres formats (CSV, TSV, XLSX, JSON).
De base, on entraîne Curie. Mais les trois autres représentants de la famille GPT-3 sont compatibles. Une fois un modèle entraîné, on peut le communiquer en paramètre à /completions. En fonction des tâches, l’entraînement nécessitera plus ou moins d’exemples : au moins 100 par catégorie pour la classification, au moins 500 pour la production de texte conditionnelle, plusieurs milliers pour de la production non contrainte, etc.

Ada, Babbage, Curie et Davinci permettent par ailleurs d’exploiter des schémas de données vectoriels. La tarification est spécifique.

OpenAI se réserve le droit d’exploiter les données fournies à ses modèles pour améliorer ces derniers. Les nouveaux utilisateurs ont un plafond initial de dépenses. Il évolue à mesure qu’on développe des usages. Lorsqu’on dépasse 5 personnes utilisant l’API, on passe en live. Une transition pas automatique, qui suppose des vérifications de type évaluation des risques.
Illustration principale © Jakub Jirsk – Fotolia





