

REEF : un framework big data open source signé Microsoft
REEF vient confirmer la volonté de Microsoft d’investir dans le big data Hadoop et plus largement la communauté open source.
Microsoft nous réserve parfois des surprise inattendues… Ainsi en est-il de REEF (Retainable Evaluator Execution Framework), un ensemble de librairies qui prend place au dessus du nouveau gestionnaire de ressources Hadoop YARN, et que l’éditeur a rendues open source.
L’après Dryad
Microsoft a pendant un temps travaillé sur une plateforme propriétaire alternative de Hadoop nommée Dryad. Associée à un modèle de programmation, DryadLINQ, et à DSC (Distributed Storage Catalog), elle était destinée à l’exécution d’applications de données sur des milliers de machines exécutant Windows HPC Server. Utilisée par le moteur de recherche Bing pour l’analyse de données non structurées, Dryad était assez proche de Hadoop, mais avec des différences notables.
REEF au dessus de YARN
REEF permet de résoudre certaines difficultés rencontrées dans YARN, la nouvelle génération de gestionnaire de ressources de Hadoop 2.0 qui aujourd’hui fait partie du projet Apache Hadoop. YARN vient se placer entre le système de fichiers HDFS et les clusters de gestion des données MapReduce, et assurer le lien entre HDFS et l’exécutions des jobs natifs dans Hadoop, comme MapReduce ou les processus de streaming Storm, ou encore l’exécutions de plusieurs processus analytiques sur une même donnée.
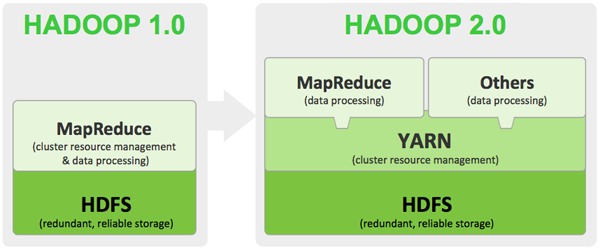
YARN présente cependant certaines limitations. En particulier, selon Raghu Ramakrishnan, CTO de la division Information Services de Microsoft, le framework est mal adaptée pour construire des jobs d’apprentissage machine car il demande des fonctionnalités spécifiques pour déplacer des données, monitorer des tâches, ou ré-itérer des calculs sans avoir à relancer le processus à chaque opération.

C’est donc là que REEF intervient. La solution se décline en deux modules : Evaluator, un ensemble de services REEF contenus dans un container YARN ; et Activity, un code utilisateur à exécuter dans un Evaluator. Cette architecture permet à l’Evaluator de demeurer original tandis que des Activities s’exécutent sur ses données. Par exemple une requête SQL qui s’exécute sur différents algorithmes d’apprentissage.
Voir aussi
Silicon.fr étend son site dédié à l’emploi IT
Silicon.fr en direct sur les smartphones et tablettes






