Existe-t-il une configuration efficace pour entraîner aussi bien un modèle d’IA que plusieurs instances en parallèle ? On trouve quelques éléments à ce sujet dans la dernière vague du benchmark MLPerf HPC. C’est la conséquence de l’inclusion d’une nouvelle métrique.
L’édition 2020 comportait un seul indicateur. En l’occurrence, le temps nécessaire à l’entraînement d’un modèle donné. Les participants avaient la possibilité d’effectuer plusieurs cycles et de moduler les résultats en écartant les résultats extrêmes.
Pas de changement sur cette métrique pour 2021. Mais MLPerf rend désormais aussi compte de la « bande passante agrégée ». Il l’exprime en nombre d’instances (d’un même modèle) entraînées par minute. Et la détermine en faisant le rapport avec le « temps total pour tout entraîner ». Celui-ci s’obtient en faisant la différence entre la durée d’entraînement de l’ultime instance à atteindre l’objectif fixé et le moment où s’est lancée celle qui l’a atteint le plus rapidement.
Le choix du nombre d’instances à entraîner en parallèle revient aux participants. Qui décident aussi de la capacité allouée à chacune d’entre elles (en unités de calcul). Et de la capacité totale disponible, en cas d’entraînement partiellement séquentiel.
Autre nouveauté 2021 : un test supplémentaire. Son nom : OpenCatalyst. Le domaine : la modélisation moléculaire quantique (découverte et évaluation de catalyseurs destinés à stocker de l’énergie). Il s’appuie sur le dataset OC20 du projet Open Catalyst. Avec, comme modèle de référence, DimeNet++, réseau neuronal génératif.
Les deux autres tests sont toujours d’actualité. D’un côté, de la segmentation climatique. De l’autre, de la prédiction cosmologique.
La deuxième métrique était facultative. Sur la trentaine de résultats publiés, huit en rendent compte : 7 en catégorie « fermée » (modèles imposés) et 1 en catégorie « ouverte » (possibilité d’optimiser les modèles).
Ce seul résultat en catégorie ouverte est attribué à Fugaku. Le supercalculateur de Fujitsu en est à 0,59 instance/minute sur le benchmark CosmoFlow, avec TensorFlow 2.2.0, une configuration à 82944 processeurs A64FX… et une modification du modèle : des couches Conv3D de 2 x 2 x 2 au lieu de 3 x 3 x 3.
Sans cette modification, et avec de plus petites instances, Fugaku atteint 1,29 modèle/minute.
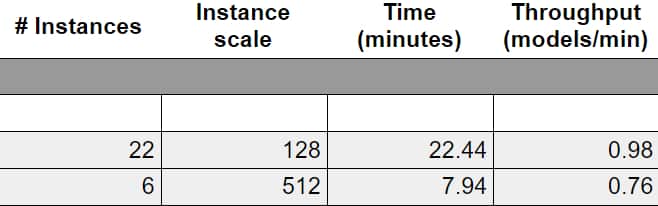
Toujours sur CosmoFlow, en catégorie fermée, on n’a pas un, mais deux indicateurs pour Juwelsbooster : 0,76 et 0,98 modèle/minute. Le supercalculateur de Helmholtz AI (collaboration entre le Centre de recherche de Juliers et l’Institut technologique de Karlsruhe) atteint ces performances sur PyTorch 1.10, avec 1536 processeurs AMD EPYC 7402 et 3072 GPU NVIDIA A100 PCIe 40 Go.
Avec son superordinateur Perlmutter, le Laboratoire national Lawrence-Berkeley atteint 0,68 modèle/minute pour CosmoFlow, sur MXNet 21.09 (version NVIDIA). Configuration : 1280 EPYC 7763 et 5120 A100 SXM4 40 Go.
Le DGX A100 de NVIDIA a aussi été mis à l’épreuve. Avec 1024 EPYC 7742 et 4096 A100 SXM4 80 Go, il s’en tire à 0,73 modèle/minute sur MXNet 21.09 (version NVIDIA).
Sur DeepCAM, on n’a de données que pour Perlmutter et DGX A100.
Le premier est à 2,06 modèles/minute avec 1280 EPYC 7763 et 5120 A100 SXM4 40 Go, sur PyTorch 21.09 (version NVIDIA).
Le second est à 5,27 modèles/minute avec 512 EPYC 7742 et 2048 A100 SXM4 80 Go, sur le même framework.
Photo d’illustration © KanawatVector – Adobe Stock
Sous la marque Horizon OS, Meta va ouvrir le système d'exploitation des casques Quest à…
Après avoir essaimé dans 145 pays, la communauté de femmes de la tech Women Who…
Les voix du CISPE et des associations d'utilisateurs s'accordent face à Broadcom et à ses…
Bonnes pratiques, indicateurs, prestataires... Aperçu de quelques arbitrages que le comité d'organisation de Paris 2024…
Le 31 mars 2023, le PTCC (Programme de transfert au Campus Cyber) était officiellement lancé.…
Nicolas Gour, DSI du groupe Worldline, explique comment l’opérateur de paiement fait évoluer sa gouvernance…
{kind=link}
{kind=link}
{kind=link}
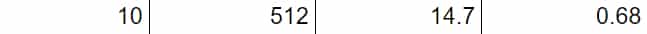{kind=link}
{kind=link}
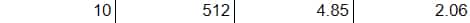{kind=link}
{kind=link}