

AlphaCode : que vaut ce concurrent de Codex made in Google ?
Développé par DeepMind (société soeur de Google), AlphaCode fera-t-il référence parmi les IA génératrices de code ?

Soit un nombre premier P. Trouvez deux entiers a et b tel que P modulo a = P modulo b et 2 ? a < b ? P. C'est l'un des problèmes auxquels DeepMind - société soeur de Google - a confronté AlphaCode.
Le rôle de ce modèle d'apprentissage automatique ? Générer du code en réponse à des problèmes algorithmiques. Et non simplement des tâches. On est donc sur des programmes potentiellement longs de plusieurs centaines de lignes.
Dans ce domaine, les benchmarks référents affichent des taux de résolution ne dépassant pas 5 %. C'est sans compter, affirme DeepMind, la proportion de faux positifs (30 à 60 %) liée au manque de tests au sein des jeux de données exploités.
Ces jeux de données proviennent généralement de compétitions dont l'objectif est précisément de répondre à de tels problèmes algorithmiques. Parmi elles, il y a Codeforces. AlphaCode a eu à travailler sur des défis proposés dans ce cadre.
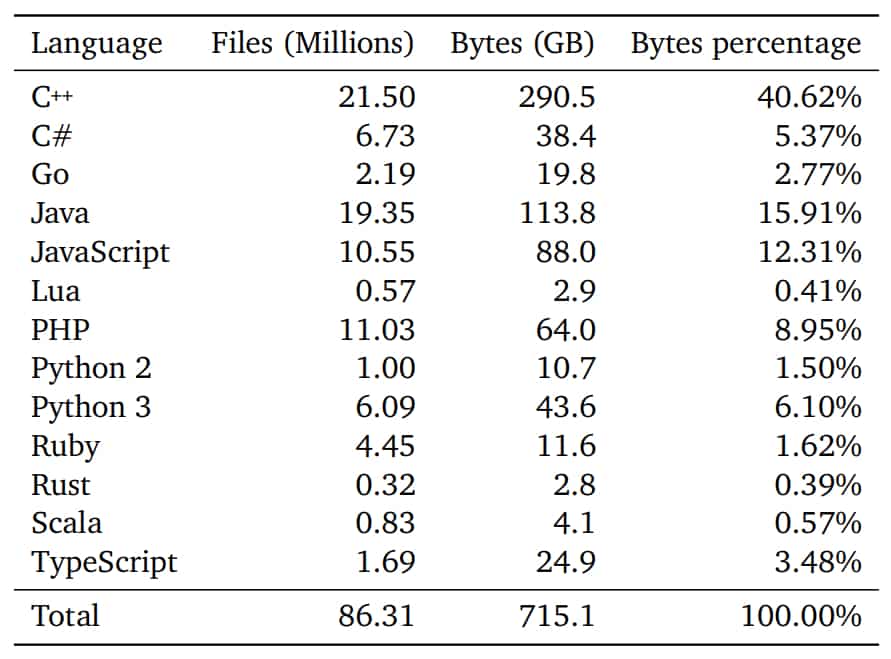
Avant de le mettre à l'épreuve, il a fallu l'entraîner. Dans un premier temps, sur 715 Go de données issues de dépôts GitHub publics. Plus précisément, un « instantané » du 14 juillet 2021 incluant des projets en C++, C#, Go, Java, JavaScript, Lua, PHP, Python, Ruby, Rust, Scala et TypeScript.

Cet entraînement a inculqué à AlphaCode les « fondamentaux » de la génération de code. Un deuxième jeu de données nommé CodeContests a permis d'en affiner les performances. Son contenu : des problèmes, des solutions et des tests issus de Codeforces et de deux autres ressources : Description2Code et CodeNet. DeepMind l'a divisé en trois sous-ensembles (entraînement, validation et test), tous pris sur des intervalles de temps distincts afin d'éviter les biais de transfert.
Dans la moyenne des développeurs
Les données publiques de Codeforces n'affichent malheureusement pas les tests dans leur intégralité lorsqu'ils dépassent les 400 caractères. Il a donc fallu en générer des supplémentaires, à partir des existants. Par exemple, en incrémentant/décrémentant des entiers ou en (é)changeant des éléments dans des chaînes de caractères.
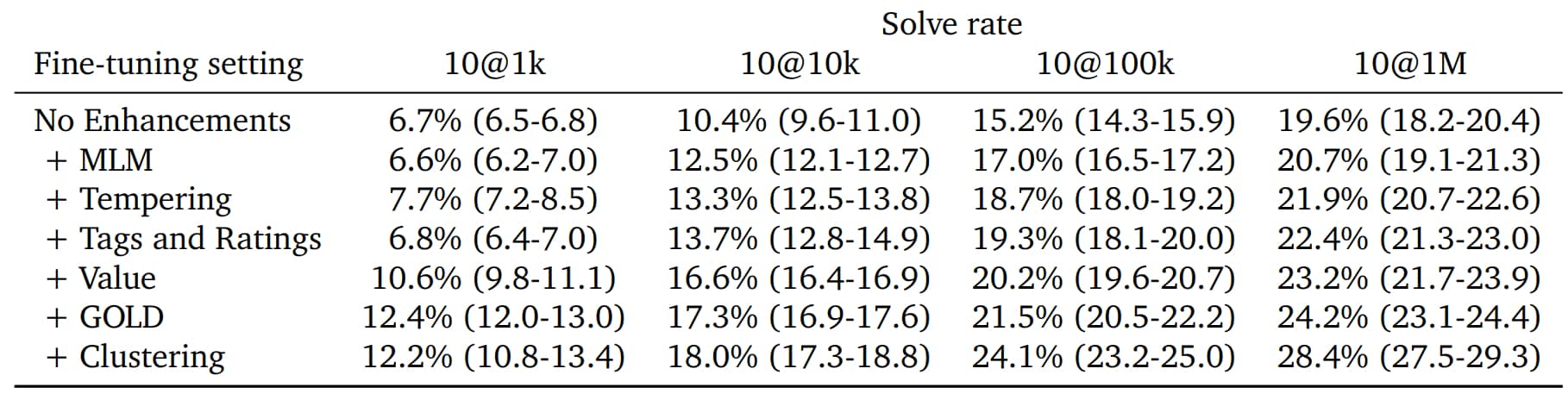
Avec un entraînement « de base », AlphaCode a des performances similaires à celles de Codex, nous explique-t-on. Il le dépasse lorsqu'on lui applique certaines techniques. Entre autres le cadrage des métadonnées, la modification de la probabilité de distribution des tokens entre encodeur et décodeur ou des indices sur la pertinence des solutions en cours d'élaboration.
Lire aussi : Gemini, ce modèle voulu multimodal « par essence »

Pour mettre au défi les différentes versions du modèle, DeepMind a récupéré dix exercices soumis récemment sur Codeforces. La phase d'inférence s'est déroulée sur une configuration à 3750 TPUv4 et 3750 TPuv4i. L'objectif : pour chaque exercice, générer massivement des solutions (une moitié en C++, l'autre en Python), ensuite filtrées en exécutant les tests fournis dans la description du problème. Un système de clustering permet de réduire encore plus l'échantillon ; l'idée étant d'en avoir 10 au maximum.

Bilan : en moyenne, sur les dix exercices, la meilleure version d'AlphaCode performe mieux que 47,7 % des candidats. Ce score est atteint avec une moyenne de 2,4 soumissions par problème.

En mettant la limite à 1 million d'échantillons, AlphaCode résout 34,2 % des problèmes du dataset CodeContests, segment « validation ».

AlphaCode, un modèle à impact environnemental
Au-delà des performances d'AlphaCode relativement aux développeurs ayant traité ces exercices, que retenir ? Notamment que :
- AlphaCode tend à réutiliser du code figurant dans les données d'entraînement, mais plus pour du traitement de données que pour de la logique pure
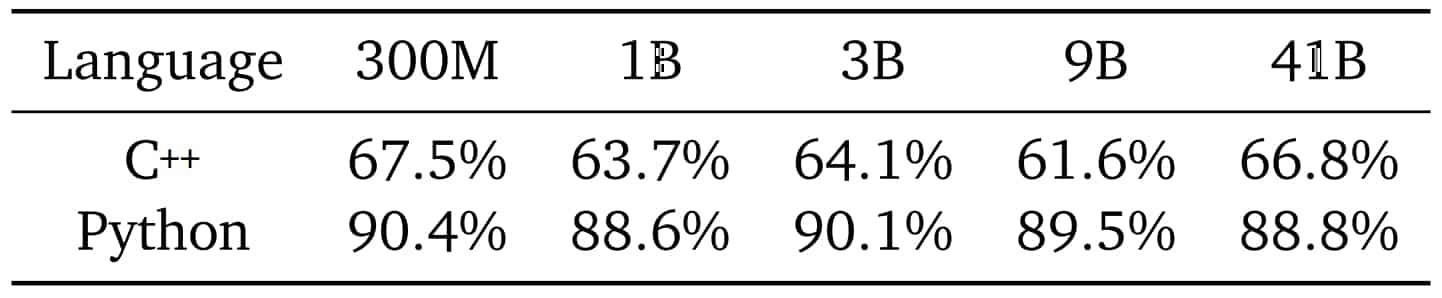
- La syntaxe n'est pas toujours correcte, en particulier pour les solutions en C++
Lire aussi : Coder avec l'IA : les lignes directrices de l'ANSSI

- AlphaCode génère à peu près la même quantité de code « inutile » qu'un humain
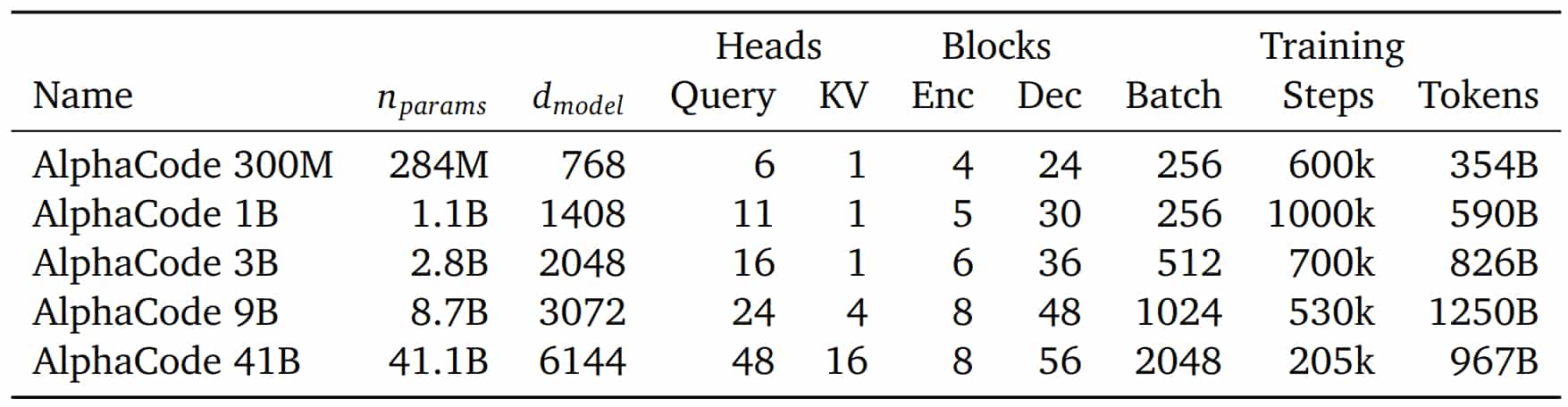
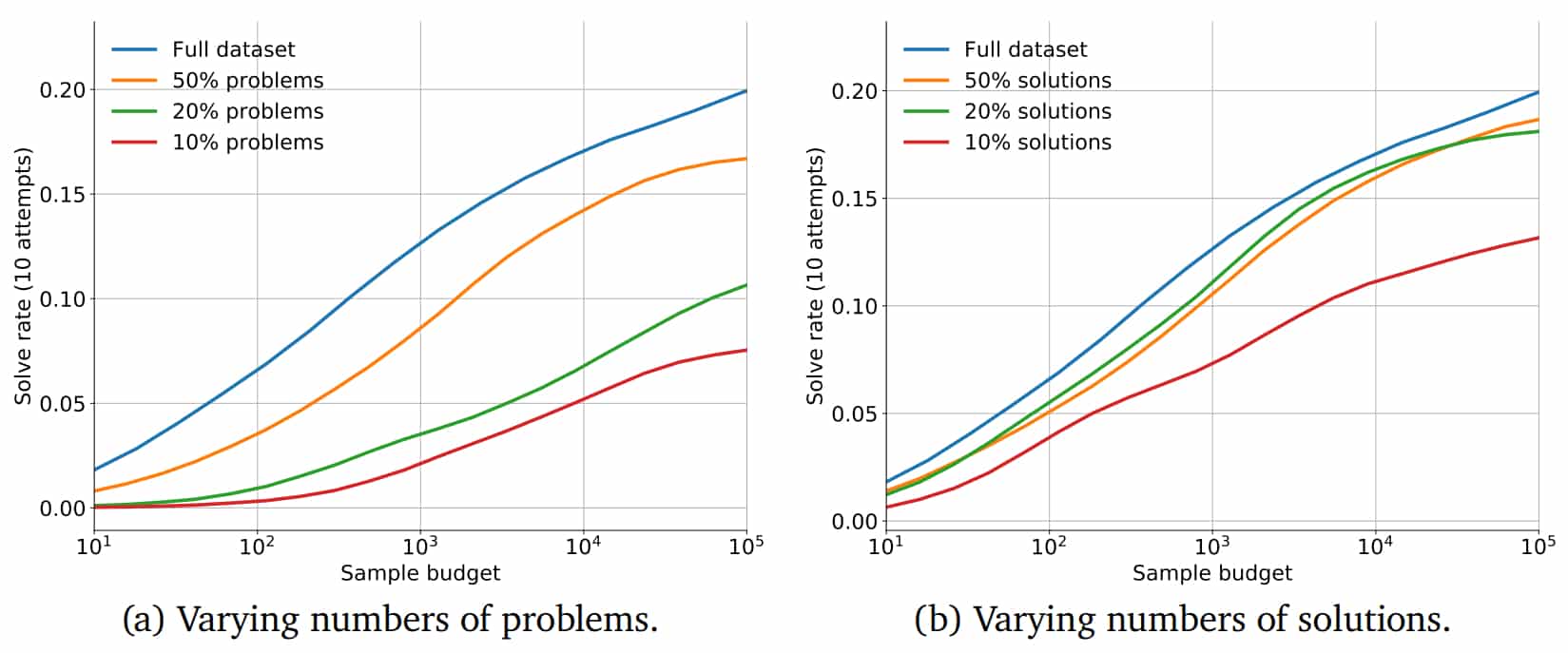
- Le taux de résolution augmente avec le nombre de paramètres (y compris quand on se limite à 10 échantillons), la puissance de calcul, le nombre d'échantillons et la taille des jeux de données
- Les modèles plus « gros » sont plus qualitatifs (ils obtiennent un meilleur taux de résolution à nombre d'échantillons égal)

- Plus la description est simple, plus le taux de résolution est haut
- L'architecture asymétrique entre encodeur et décodeur améliore la vitesse d'échantillonnage

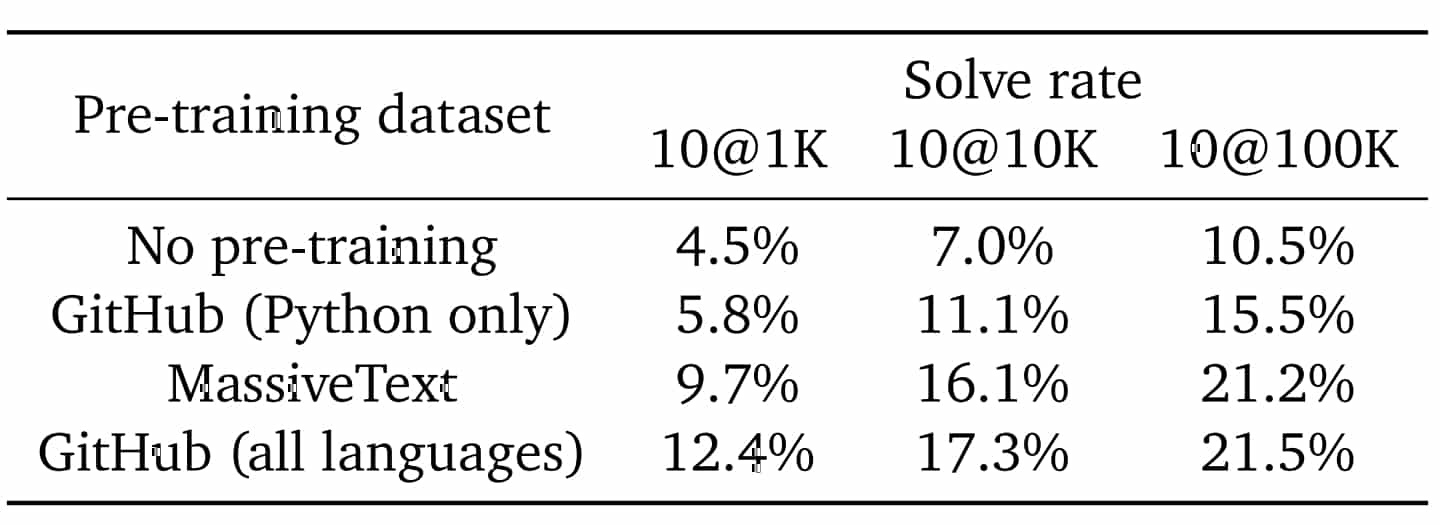
- Les résultats sont bien meilleurs quand on entraîne les modèles sur de multiples langages de programmation, y compris ceux non ciblés en sortie

- Sans filtrage, moins de 1 % des propositions réussissent les tests
- AlphaCode a un impact environnemental non négligeable : l'entraînement et l'échantillonnage ont consommé des centaines de jours/pétaFlops. Malgré cela, le modèle à 41 milliards d'hyperparamètres n'a pas pu être entraîné au même niveau que les autres, au nom de la frugalité.
Illustration principale © Florian Olivo - Unsplash
Sur le même thème
Voir tous les articles Data & IA
Par Clément Bohic
Par Clément Bohic
Par Clément Bohic
Par La rédaction
Par Clément Bohic







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}