

D'ATT@CK à D3FEND : un framework de cybersécurité en appelle un autre
À son framework ATT@CK lancé en 2013, MITRE a ajouté, l'an dernier, D3FEND, axé sur les techniques de défense.

Comment représenter différentes approches destinées à résoudre un même problème ? Chez MITRE, la question s'est posée lors de l'élaboration du framework de cybersécurité D3FEND.
L'organisation américaine est plus connue pour un autre référentiel. En l'occurrence, ATT@CK (« Adversarial Tactics, Techniques and Common Knowledge). Ce dernier, né en 2013, qui apporte des informations sur le comportement des attaquants.
D3FEND (« Detection, Denial and Disruption Framework Empowering Network Defense ») est bien plus récent (lancé mi-2021). Encore en version expérimentale, il répertorie des techniques défensives. Son premier objectif : aider à standardiser le vocabulaire utilisé pour décrire ces techniques. En l'état, MITRE lui prête deux usages :
- Analyser les fonctionnalités de produits de cybersécurité
- Grâce à une passerelle avec ATT@CK, déterminer comment ces produits mettent leurs fonctionnalités en application
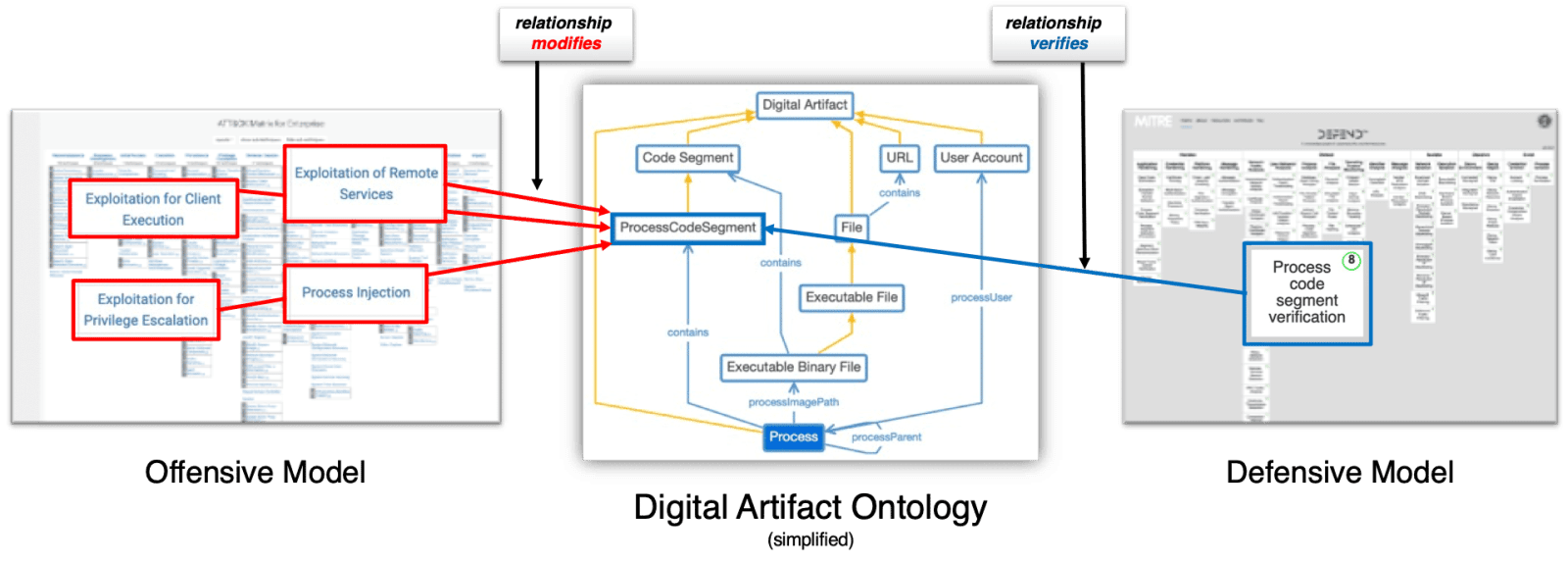
Le modèle sémantique de D3FEND reprend pour partie celui d'ATT@CK. Pour le moment, les liens établis entre les deux frameworks résultent essentiellement de généralisations. L'idée à terme est d'y appliquer du machine learning semi-supervisé.
La matrice D3FEND
Comme ATT@CK, D3FEND se divise en cinq « tactiques », elles-mêmes sous-divisées en « techniques ». Dans les grandes lignes :
1 - Renforcement de la sécurité
- Applications (élimination du code mort, authentification des pointeurs...)
- Informations d'identification (biométrie, certificats...)
- Messages (authentification, chiffrement...)
- Plates-formes (intégrité des pilotes, permissions locales...)
2 - Détection
- Fichiers (analyse dynamique, hachage...)
- Identifiants (réputation des IP, des noms de domaines...)
- Messages (réputation des MTA, des expéditeurs...)
- Trafic (métadonnées de protocoles, ration téléchargement/téléversement par hôte...)
- Plate-forme (comportement du firmware, gestion de la mémoire...)
- Processus (branchements indirects, exécution de scripts...)
- Utilisateurs (durée des sessions, monitoring local...)
3 - Isolation
- Exécution (matérielle, noyau, restriction des I/O...)
- Réseau (domaines de diffusion, tunnels chiffrés...)
4 - Leurres
- Environnements (pots de miel)
- Objets (faux fichiers, tokens, ressources réseau...)
Lire aussi : La roadmap d'OpenSearch sous l'ère Fondation Linux
5 - Suppression
- Informations d'identification (verrouillage de compte, invalidation de cache d'authentification...)
- Processus (arrêt)
Principale source : un corpus de « plus de 500 brevets » déposés aux États-Unis entre 2001 et 2018. Une source que MITRE considère comme plus précise que les livres blancs et autres supports émanant des offreurs. Sans nier que les éléments qui y figurent sont, par opposition au cas des rapports académiques, choisis pour mettre en avant la nouveauté et l'utilité des technologies.
Dans l'absolu, la « marge de progression » est grande si on considère que la base de brevets prise en compte regroupe plusieurs dizaines de milliers d'éléments. Et que MITRE a croisé cet ensemble avec d'autres ressources (conférences, blogs, revues spécialisées).
Le focus initial a porté sur les fournisseurs spécialisés dans la détection. La réflexion s'est axée sur deux aspects : le coeur fonctionnel et l'interaction utilisateur. C'est là que MITRE a constaté la variété des approches face à un même problème. Il en donne l'exemple à propos de la segmentation des processus : quelle est la source de vérité pour s'assurer que les fragments de code sont bien ceux attendus ? Que se passe-t-il si certains sont jugés invalides ?...
Illustration principale © pinkeyes - Adobe Stock
Sur le même thème
Voir tous les articles Cybersécurité![Gestion des accès à privilèges (PAM) : ce qui progresse à part [...]](https://cdn.edi-static.fr/image/upload/c_lfill,h_201,w_298/e_unsharp_mask:100,q_auto/f_auto/v1/Img/BREVE/2024/9/463597/Gestion-acces-privileges-PAM-qui-progresse--L.jpg)
Par Clément Bohic
Par Adrien Merveille
Par Clément Bohic
Par La rédaction
Par Clément Bohic







{kind=link}