

Google I/O : Dataflow alimente en temps réel Big Query en Big Data
Après la mobilité, Google a parlé du Big Data lors de son évènement développeurs. La firme a dévoilé le service Dataflow qui permet d'injecter des flux de données à la volée dans l'outil Big Data maison, Big Query.
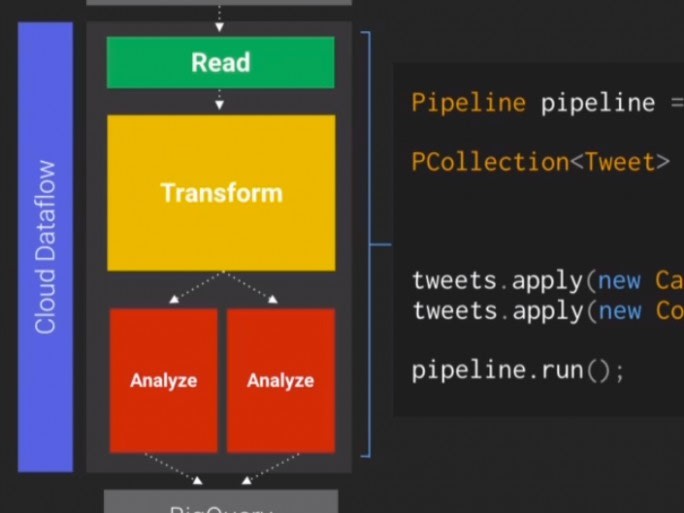
Il y a une vie en dehors d'Android. A Google I/O, les développeurs ont pu également se concentrer sur le Big Data. La firme de Mountain View a en effet présenté un service nommé Cloud Dataflow, un outil intégré dans Cloud Platform et qui permet d'analyser des flux de données à la volée.
Dans un billet de blog, Greg DeMichillie, responsable produit, a expliqué que « ce service est basé sur deux technologies internes à Google, Flume et Millwheel ». La première est capable de créer des « pipelines » de données issues de sources différentes et l'autre facilite le transit des données. A l'occasion de la conférence, Urs Hölzle, responsable de la création du réseau mondial de datacenters de Google, a souligné que ce service permet aux entreprises de faire face à des pétaoctets de données. « Cloud Dataflow est le résultat de plus d'une décennie d'expérience dans l'analyse de données », précise le dirigeant. Sur scène, il a fait la démonstration de cette solution en analysant en temps réel le ressenti des personnes sur Twitter lors du match d'ouverture de la coupe du monde de football au Brésil.
Un successeur à MapReduce
Urs Hölzle a continué son exposé en expliquant que « depuis longtemps, Google travaillait avec le système MapReduce qui est devenu la norme pour le traitement Big Data. Il a parcouru des centaines de serveurs pour nous aider à construire un gigantesque index des pages web qui sous-tend notre moteur de recherche. Maintenant, nous avons un clone Open Source de MapReduce-Hadoop ». Il ajoute, « Google n'utilisera plus MapReduce mais Flume, alias FlumeJava pour le traitement de données massives en mode batch ».
Disponible en version bêta, Dataflow pourra se brancher directement sur Big Query, la solution Big Data as a Service de Google. Cette initiative n'est pas unique comme le montre le service de streaming MapReduce de Twitter baptisé Summingbird et présenté en septembre 2013. Amazon Web Services propose également une offre en mode similaire à Dataflow, Kinesis permettant de traiter en temps réel des données récoltées en continu à une échelle massive. Les données peuvent ensuite être envoyées vers différents services, notamment Amazon S3, DynamoDB et Redshift (solutions d'entreposage de données).
A lire aussi :
Luc de Brabandere, « Le Big Data est un outil de découverte pas d'invention »
Sur le même thème
Voir tous les articles Data & IA
Par La rédaction
Par La rédaction
Par Clément Bohic
Par La rédaction
Par Clément Bohic






