En novembre dernier, Microsoft annonçait des avancées dans le domaine du traitement automatique du langage naturel sur son moteur de recherche Bing.
Il a décidé d’en faire bénéficier les développeurs, en les intégrant à ONNX Runtime.
Ce moteur d’inférence est open source depuis novembre 2018. Il est destiné à exécuter des modèles au format ONNX (Open Neural Network Exchange ; format que Microsoft et Facebook avaient lancé en 2017 pour favoriser la portabilité des algorithmes de deep learning entre frameworks IA).
La version 1.1.0, publiée il y a quelques semaines, embarque les avancées en question. Elles portent sur le modèle de langage BERT (Bidirectional Encoder Representations from Transformers), né à l’initiative de Google.
Microsoft exploite BERT à plusieurs niveaux de son moteur de recherche. Entre autres :
Par opposition aux réseaux neuronaux « traditionnels » qui traitent les mots les uns après les autres, les « transformateurs » tels que BERT interprètent les relations entre un mot et ses voisins. Problème : mis à l’échelle d’un moteur de recherche, ils posent des problèmes de coût et de performances.
Intégré tel que dans Bing, BERT aurait requis des dizaines de milliers de serveurs pour traiter des millions de requêtes par seconde avec une latence acceptable.
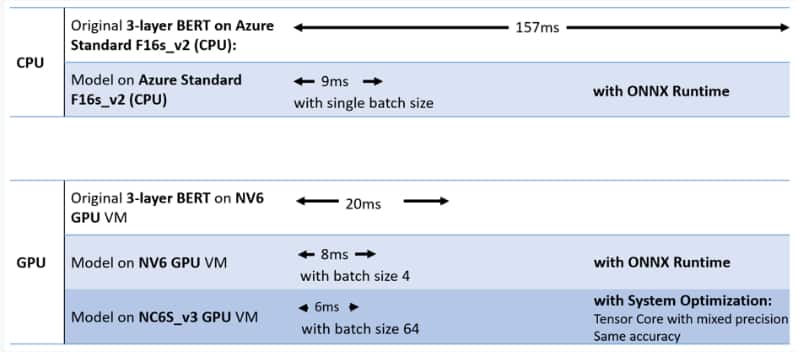
En s’appuyant sur ses VM Azure série N, Microsoft en a amélioré l’exécution sur GPU pour favoriser le calcul parallèle.
Sur les VM NV6, la latence d’inférence a été divisée par près de 4, passant de 77 ms (après optimisation sur CPU) à 20 ms (sur GPU).
Réimplémenté grâce aux API C++ TensorRT en partenariat avec Nvidia, le modèle a pu réaliser 4 inférences en 9 ms.
En exploitant la technologie Tensor Core de Nvidia sur les VM NC6s_v3, la latence est passée à 6 ms pour un lot de 64 opérations d’inférence.
À ce niveau de performance, quelque 200 VM Azure on permis de traiter 1 million de requêtes par seconde à l’échelle mondiale.
À travers ONNX Runtime, Microsoft propose ces optimisations dans des versions « améliorées » au sens où elles fonctionnent également sur CPU.
Photo d’illustration © Natalia Shepeleva – Shutterstock.com
Microsoft expérimente, sous la marque ZTDNS, une implémentation des principes zero trust pour le trafic…
Accord de principe entre créanciers, propositions de reprise, discussions avec l'État... Le point sur le…
Un temps pressenti pour constituer le socle d'une suite bureautique AWS, Amazon WorkDocs arrivera en…
Eviden regroupe cinq familles de serveurs sous la marque BullSequana AI. Et affiche le supercalculateur…
Le dernier Magic Quadrant du SSE (Secure Service Edge) dénote des tarifications et des modèles…
Formats de paramètres, méthodes d'apprentissage, mutualisation GPU... Voici quelques-unes des recommandations de l'ANSSI sur l'IA…
{kind=link}