Comment rendre moins coûteux l’apprentissage par renforcement ? En permettant aux algorithmes d’exploiter plus efficacement les ressources à leur disposition.
Google aborde la problématique à travers le projet SEED RL, dont il vient d’officialiser la mise en open source.
À la base de ces travaux, un modèle (ou agent) d’apprentissage par renforcement que sa filiale DeepMind avait dévoilé voilà deux ans : IMPALA.
Ce dernier repose sur une architecture dite « acteur-critique ».
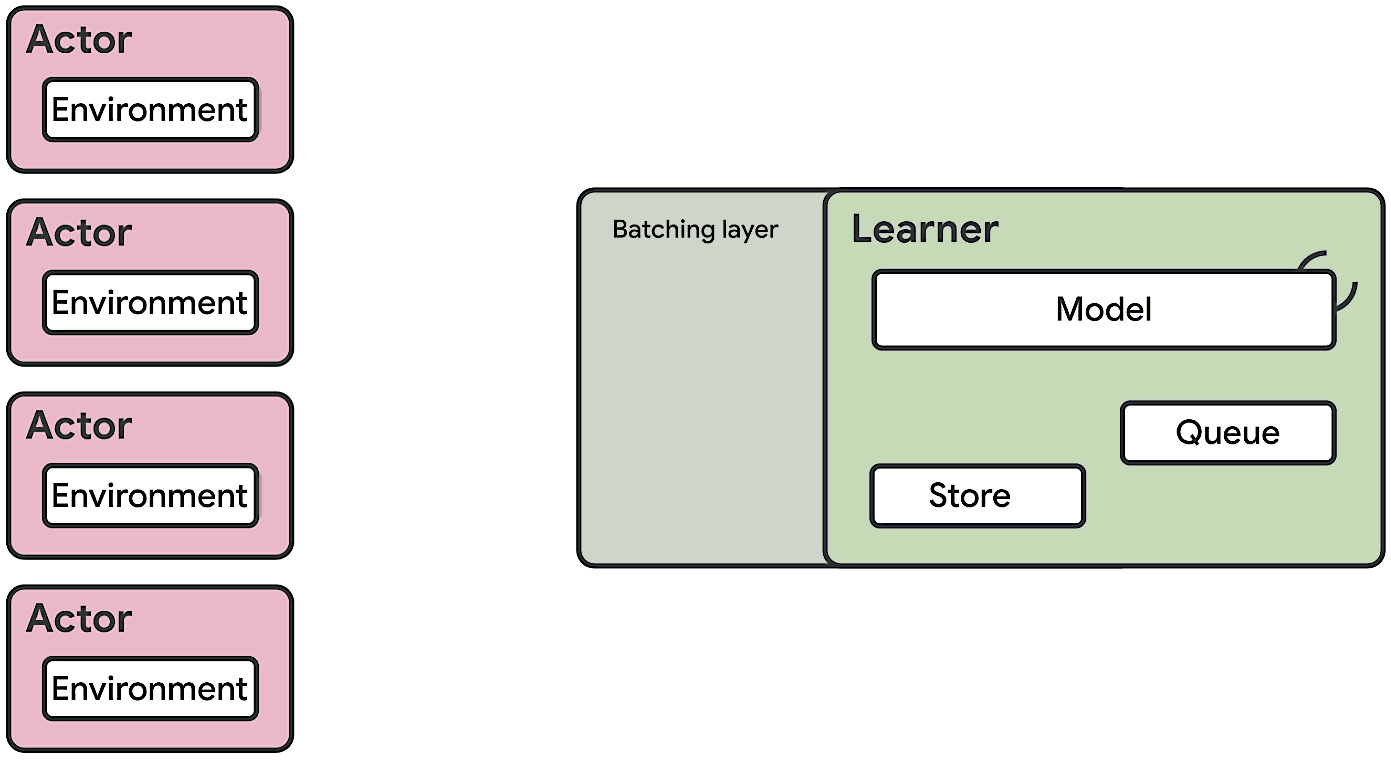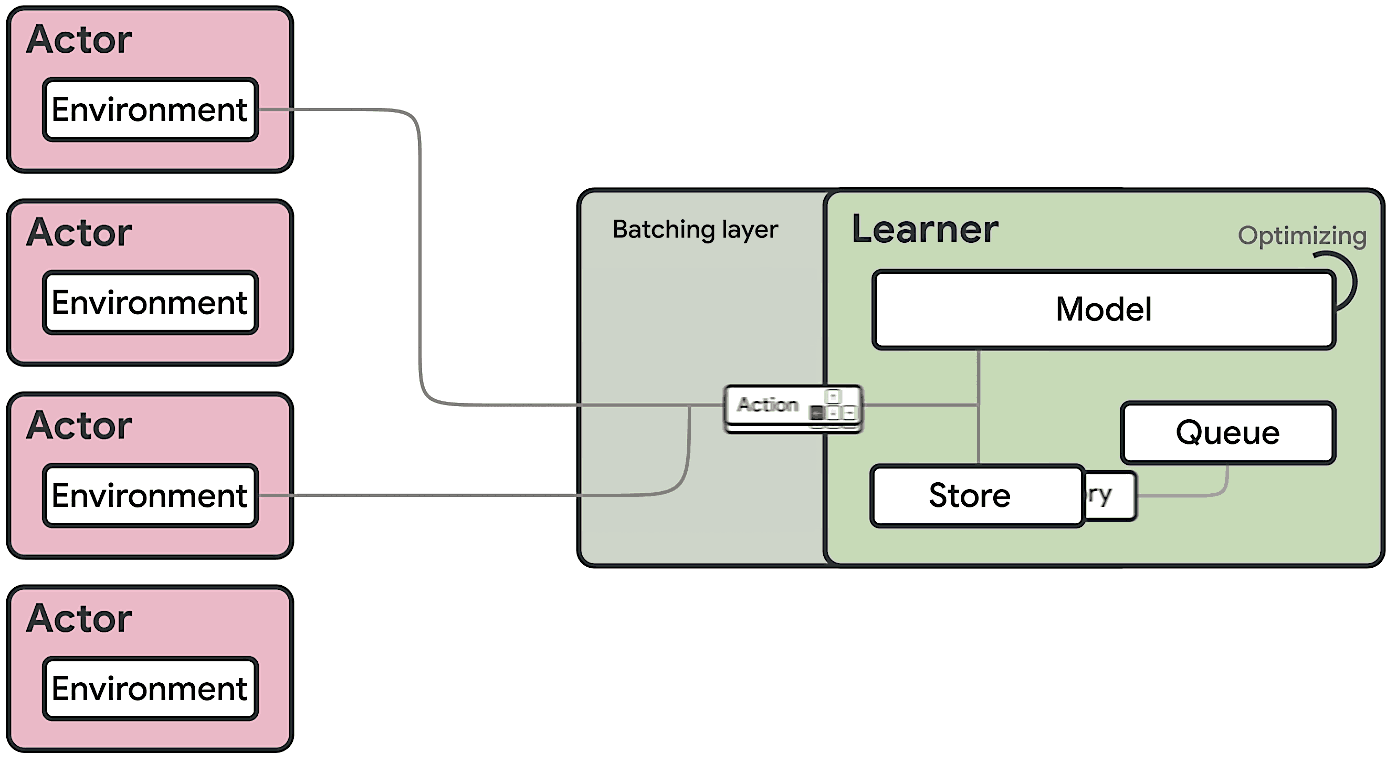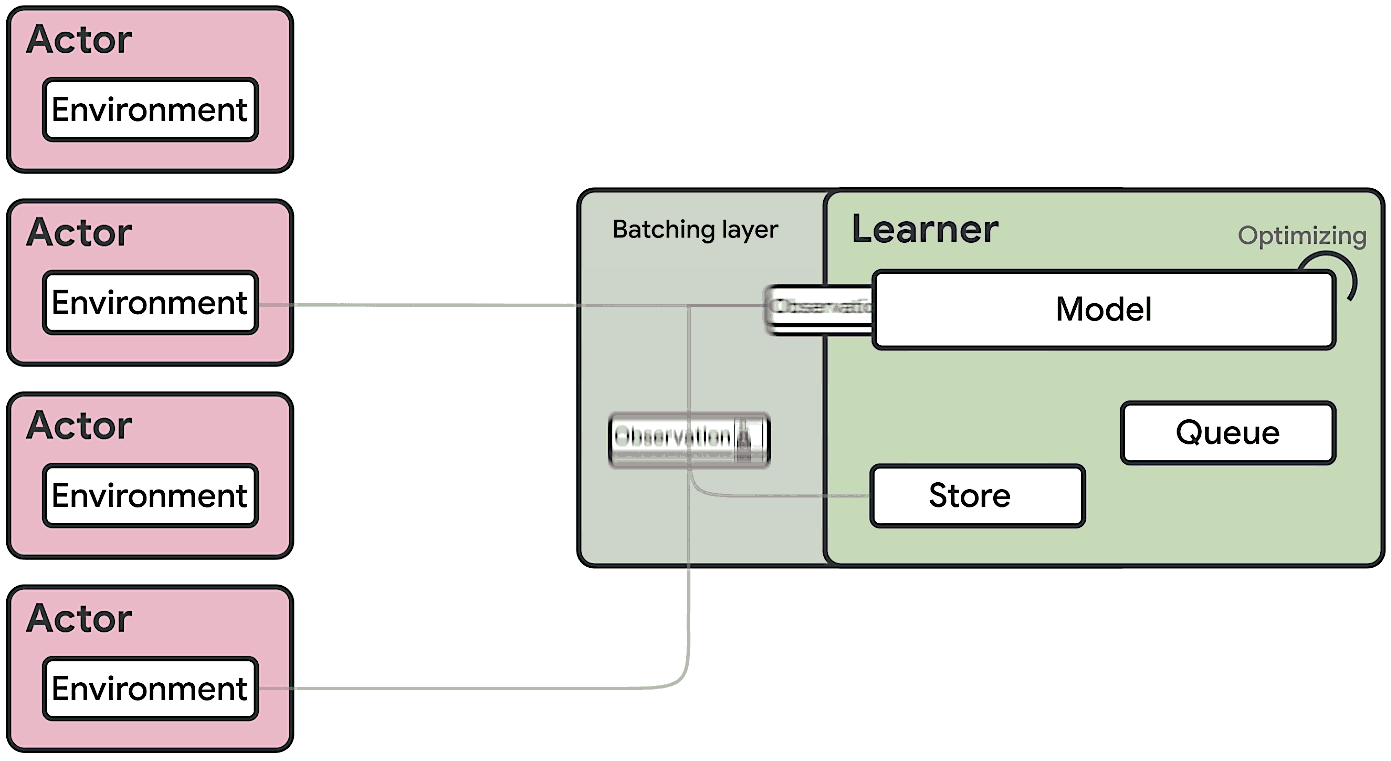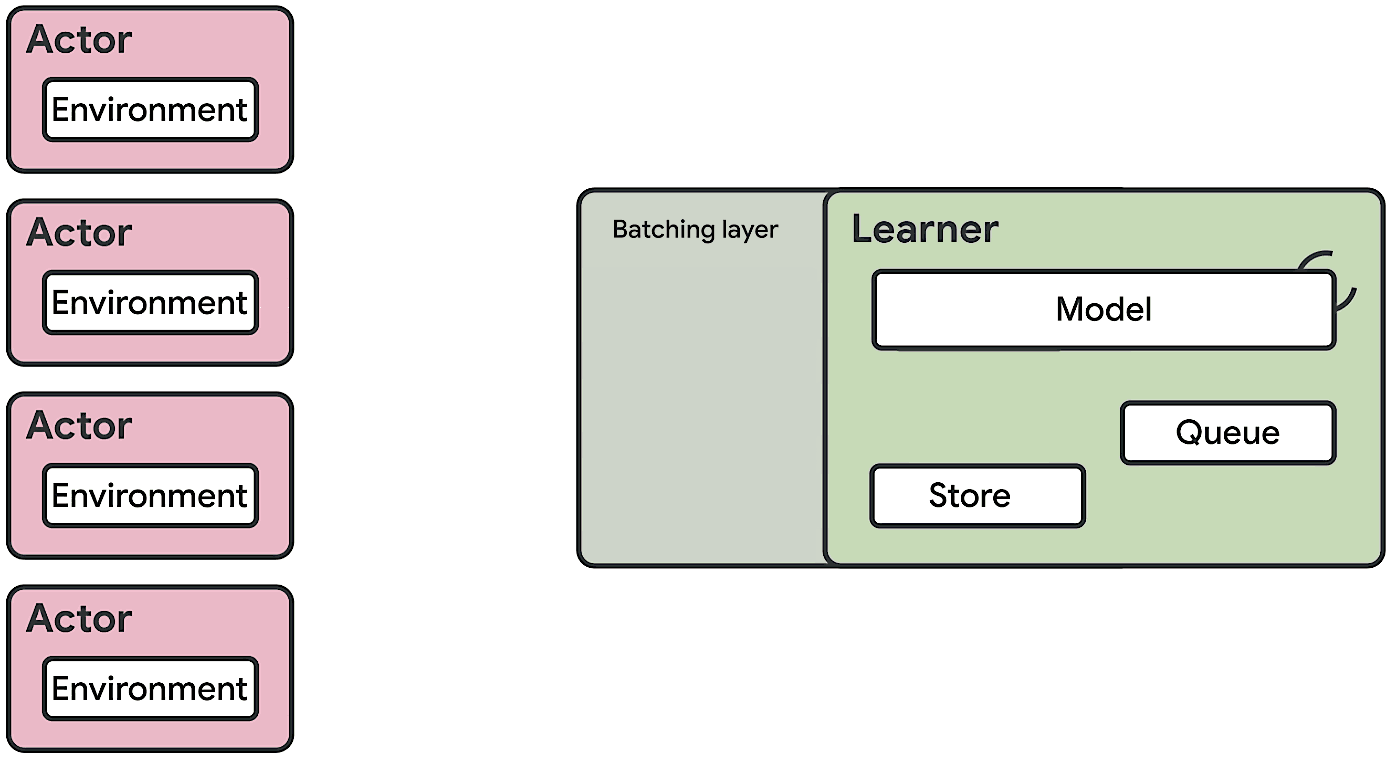
Divisé en une multitude de sous-agents déployés en parallèle sur des milliers de machines, l’acteur a pour rôle d’explorer un environnement et d’en tirer des expériences à partir d’une politique.
Ces séquences d’états, d’actions et de récompenses, il les transmet à un apprenant centralié (le critique) qui traite les expériences et améliore la politique.
Traditionnellement, on fait tourner les acteurs sur des CPU. Les critiques, moins nombreux, s’exécutent sur des GPU.
Une telle architecture présente, d’après Google, des inconvénients :
SEED RL remodèle cette architecture avec deux points principaux :
Comme IMPALA, SEED RL exploite V-trace. Cet algorithme de correction hors politique permet de normaliser l’apprentissage des agents pour éviter la décohérence temporelle.
Sur l’environnement DeepMind Lab, Google annonce 2,4 millions de trames traitées par seconde avec 64 cœurs TPU (du nom de ses puces dédiées à l’IA). IMPALA requiert trois à quatre fois plus de ressources pour atteindre la même vitesse.
Photo d’illustration © mikemacmarketingviaVisualHunt / CC BY
Un an et demi après sa publication initiale, le RGESN est mis à jour. Tour…
Le régulateur britannique de la concurrence renonce à une enquête approfondie sur le partenariat de…
À partir de juillet 2024, Microsoft imposera progressivement le MFA pour certains utilisateurs d'Azure. Aperçu…
La pépite française de l'informatique quantique Pasqal va installer un ordinateur quantique de 200 qubits…
Le fonds de pension australien UniSuper a vu son abonnement Google Cloud supprimé - et…
OpenAI orchestre un déploiement très progressif de GPT-4o, y compris de ses capacités multimodales.
{kind=link}
{kind=link}