Qui sera le meilleur pour exploiter MASSIVE ? C’est l’objet d’une compétition à deux volets qu’organise Amazon. Le but : faire émerger des modèles d’interprétation du langage naturel polyglottes.
L’initiative n’est pas – et de loin – une première. Mais elle repose sur un jeu de données voulu plus « solide » que ceux sur lesquels se sont fondées de précédentes expérimentations.
Ce jeu de données, c’est MASSIVE (Multilingual Amazon SLU resource package for Slot-filling, Intent classification, and Virtual assistant Evaluation). Il n’est pas né de rien. Il s’agit en l’occurrence d’une extension de SLURP (Spoken Language Understanding Resource Package). Couvrant le même nombre de domaines, les mêmes types d’intentions, à peu près la même quantité d’échantillons… mais étendu à une cinquantaine de langues (contre uniquement l’anglais pour SLURP).
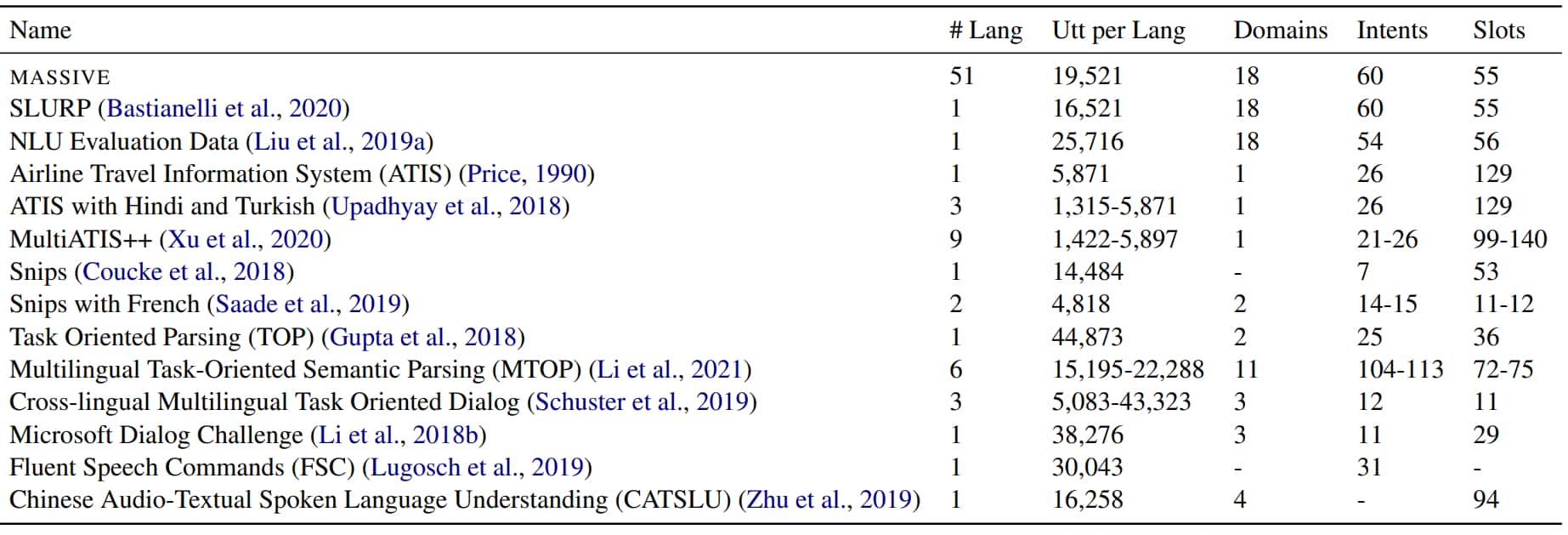
On recense d’autres initiatives d’extension de jeux de données linguistiques. Le tableau ci-dessus en présente quelques-unes. La référence ATIS, par exemple, a fait l’objet d’une adaptation en MultiATIS++, limitée néanmoins à la réservation de billets d’avion.
En 2019, Facebook avait dégainé son propre jeu de données ciblant les assistants vocaux. Il était plus transversal, couvrant notamment les rappels, les alarmes et la météo. Mais le rapport entre les langues était déséquilibré (5 000 échantillons en thaï contre 43 000 en anglais, par exemple).
Avec MASSIVE (publié sous licence CC BY 4.0), Amazon élimine cet écueil : chaque langue a le même nombre d’occurrences. Le groupe américain s’est, pour cela, appuyé sur sa plate-forme de microtravail Mechanical Turk (MTurk). Il a restreint sa sélection de langues sur plusieurs critères. Dont :
– Pour chacune, coût et disponibilité des travailleurs sur la plate-forme
– Disponibilité de chaque langue sur les principaux assistants virtuels (afin de disposer d’un support de test ultérieur)
– Diversité des alphabets, pour mieux expérimenter la tokenisation et la normalisation
– Diversité des genres de langues (= groupes de langues qu’on peut associer au sein d’une famille sans recourir à des méthodes complexes de linguistique)
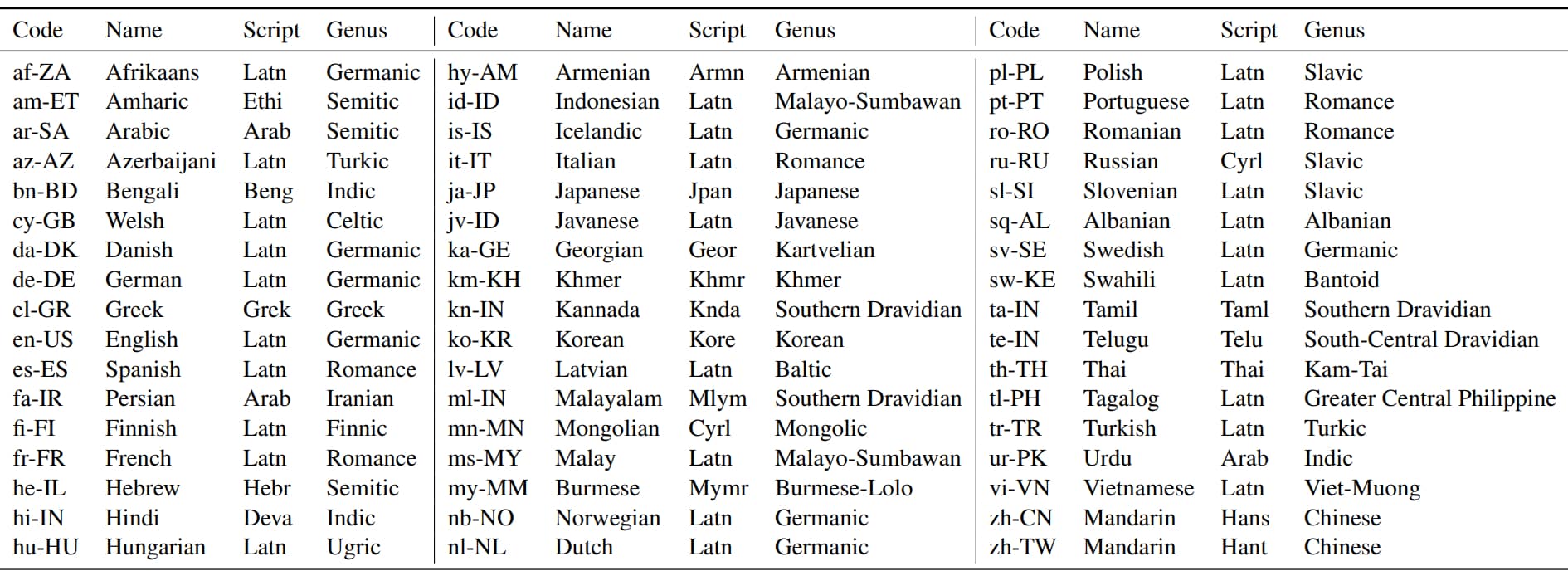
La sélection finale englobe 14 familles de langues (isolats compris). Pour 21 types d’alphabets (28 dérivés du latin, 3 de l’arabe, 2 du cyrillique). Le mandarin est représenté deux fois (écritures traditionnelle et simplifiée). Se destinant à des appareils plutôt qu’à des personnes, les phrases sont essentiellement de nature impérative et interrogative.
Avant l’étape MTurk, Amazon a prélevé aléatoirement un sous-ensemble d’échantillons de SLURP. Et a sollicité des professionnels pour les paraphraser, obtenant ainsi des occurrences plus complètes (+49 % d’entités identifiables, notamment).
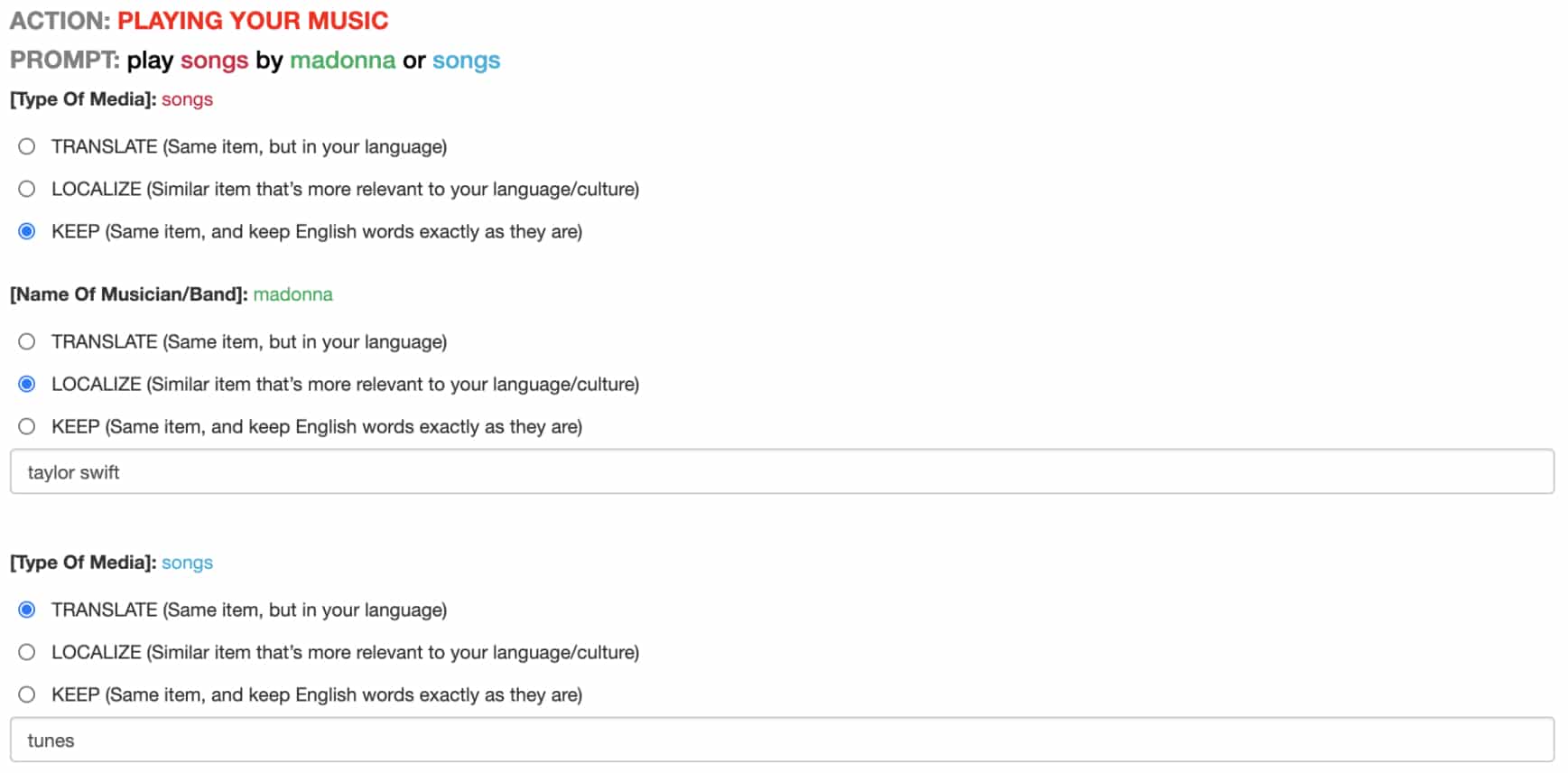
Sur MTurk, trois tâches ont été réalisées :
– Traduction ou localisation de fragments
– Traduction ou localisation de phrases
– Contrôle qualité (triple passe)
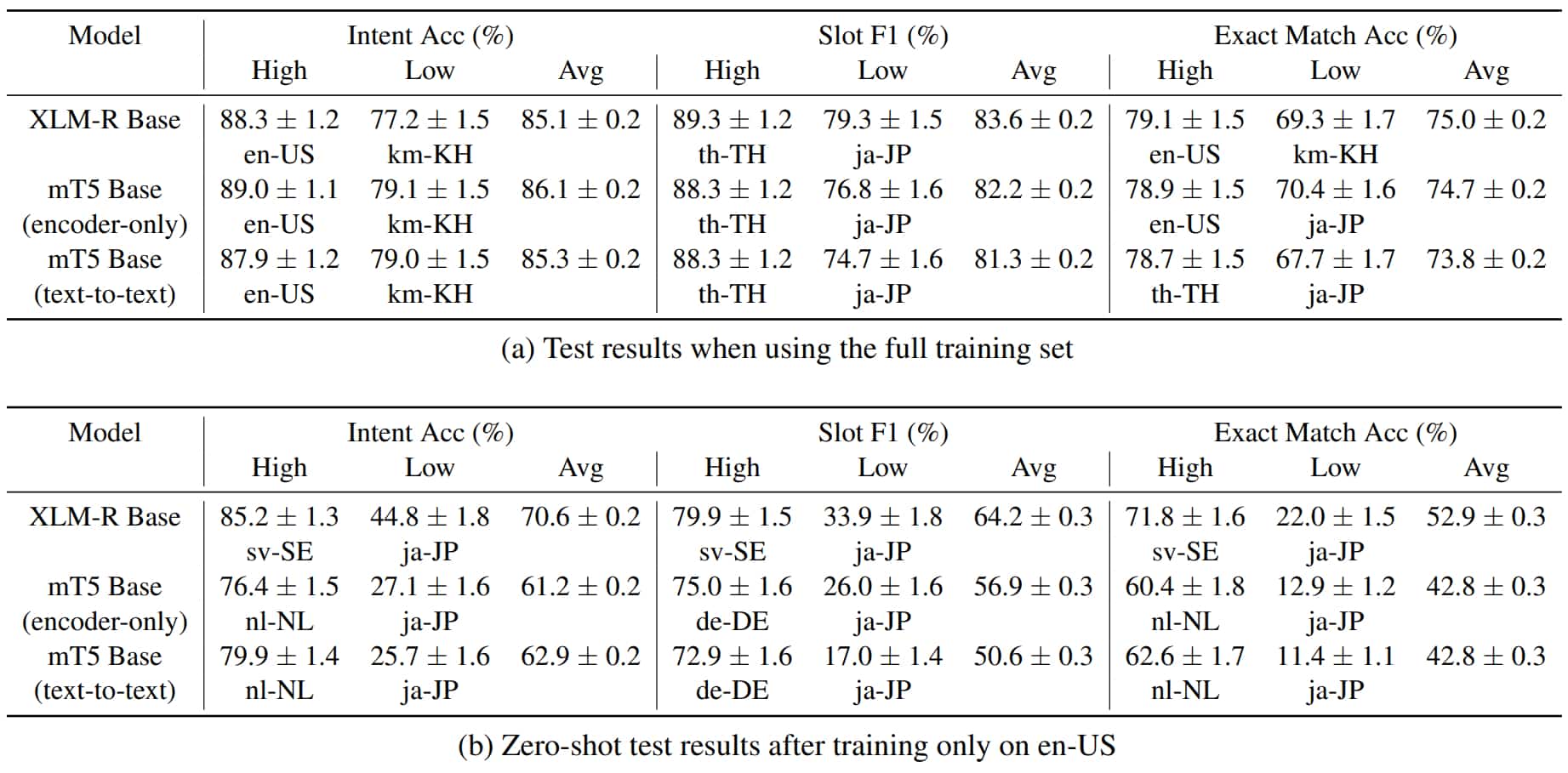
Amazon a mis MASSIVE à l’épreuve sur deux modèles existants : XLM-R et mT5. Avec deux tests : classification d’intention et prédiction de fragments. Et deux méthodes : entraînement complet ou zero-shot (entraînement uniquement sur l’anglais américain, validation sur toutes les langues, tests sur toutes les locales non anglaises).
Avec XLM-R, il a été décidé de réutiliser l’encodeur et d’y associer deux classificateurs fondés sur JointBERT. Avec mT5, deux architectures ont été explorées. L’une sur le même modèle que XLM-R ; l’autre impliquant l’ensemble du modèle (encodeur et décodeur). Dans tous les cas, le modèle avait la taille de base (270 millions d’hyperparamètres pour XLM-R ; 258 millions pour mT5-encodeur et 580 millions pour mT5 dans son ensemble).
Au global, les performances sont meilleures sur les langues germaniques et les alphabets latins – logique au vu du volume de données d’entraînement. Pour les langues sans espaces, Amazon en a introduit des « artificiels » au moment des tests. Cela s’est révélé utile en thaï… mais moins en japonais : la technique excluant toute vectorisation d’ensembles de caractères, les performances en correspondance exacte peuvent varier du simple au triple entre entraînement complet et zero-shot.
La compétition sus-évoquée comprend un classement permanent fondé sur la partie test de MASSIVE. Et un événement qui aura lieu cet été, sur la base d’un jeu de données spécifique pas encore public.
Illustration principale © Amazon
Le voile est levé sur Oracle Code Assist. Présenté comme spécialisé en Java et SQL,…
EPEI, la société d'investissement de Daniel Kretinsky, a déposé une offre de reprise d'Atos. En…
Onepoint, l'actionnaire principal d'Atos, a déposé une offre de reprise du groupe. En voici quelques…
Broadcom a repris seul la main sur la vente de l'offre VMware d'AWS... qui, dans…
Microsoft expérimente, sous la marque ZTDNS, une implémentation des principes zero trust pour le trafic…
Accord de principe entre créanciers, propositions de reprise, discussions avec l'État... Le point sur le…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}