Peut-on concevoir des grands modèles de langage performants en ne les entraînant que sur des données publiques ? C’est l’un des angles sous lesquels l’équipe Meta AI présente LLaMA.
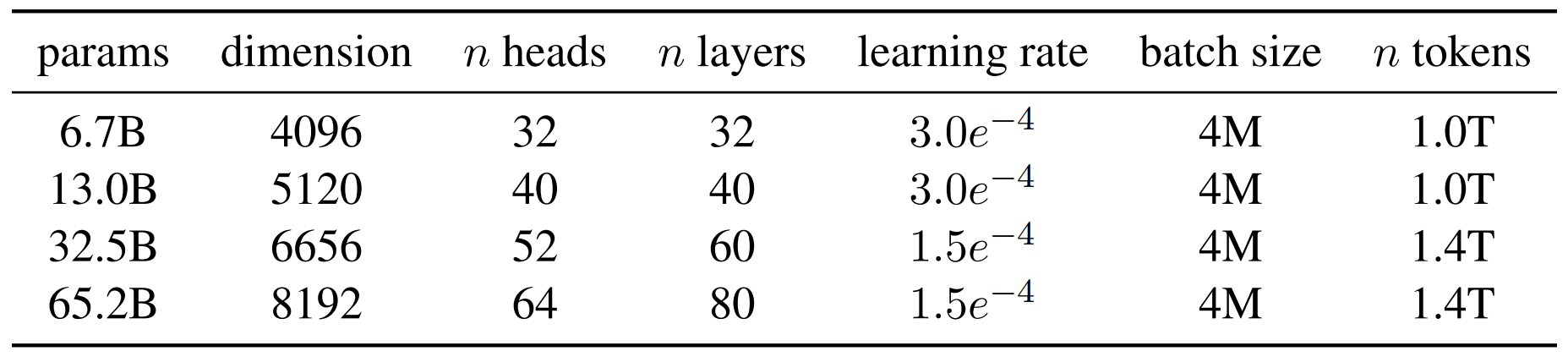
Sous cette ombrelle se trouvent quatre modèles dont le plus lourd pèse 65,2 milliards de paramètres. Ils ne sont pour le moment accessibles que sur demande. Avec une licence spécifique n’autorisant l’exploitation, la reproduction et la (re)distribution qu’à des fins de recherche non commerciale.
Le dataset d’entraînement reprend pour l’essentiel les sources qui ont servi à former d’autres LLM référents. Mais avec, donc, uniquement des données publiques et republiables. Elles sont issues, pour un peu plus des deux tiers, de dumps de Common Crawl filtrés à plusieurs niveaux (déduplication, suppression des langues autres que l’anglais, élimination du contenu de basse qualité). Le reste comprend notamment :
– Corpus de livres (projet Gutenberg et un sous-ensemble de ThePile)
– Données scientifiques (ArXiv)
– Base de questions-réponses (StackExchange)
– Dataset GitHub public disponible sur BigQuery
Au final, le jeu de données représente environ 1400 milliards de tokens. Sur la plupart d’entre eux, les modèles LLaMA ont subi un cycle d’entraînement. Pour la version à 65 milliards de paramètres (que nous appellerons LLaMA-65B), il a fallu environ trois semaines à raison de 380 000 tokens/seconde/GPU sur une configuration à 2048 NVIDIA A100 80 Go.
La mise à l’épreuve s’est faite sur une vingtaine de benchmarks. Soit en zero-shot (sans exemples), soit en few-shot (1 à 64 exemples). Avec pour missions de compléter des phrases ou de choisir l’option la plus appropriée à un contexte. Parmi ses adversaires, des modèles non publiés (GPT-3, Gopher, Chinchilla, PaLM) et d’autres ouverts (OPT, GPT-J, GPT-Neo).
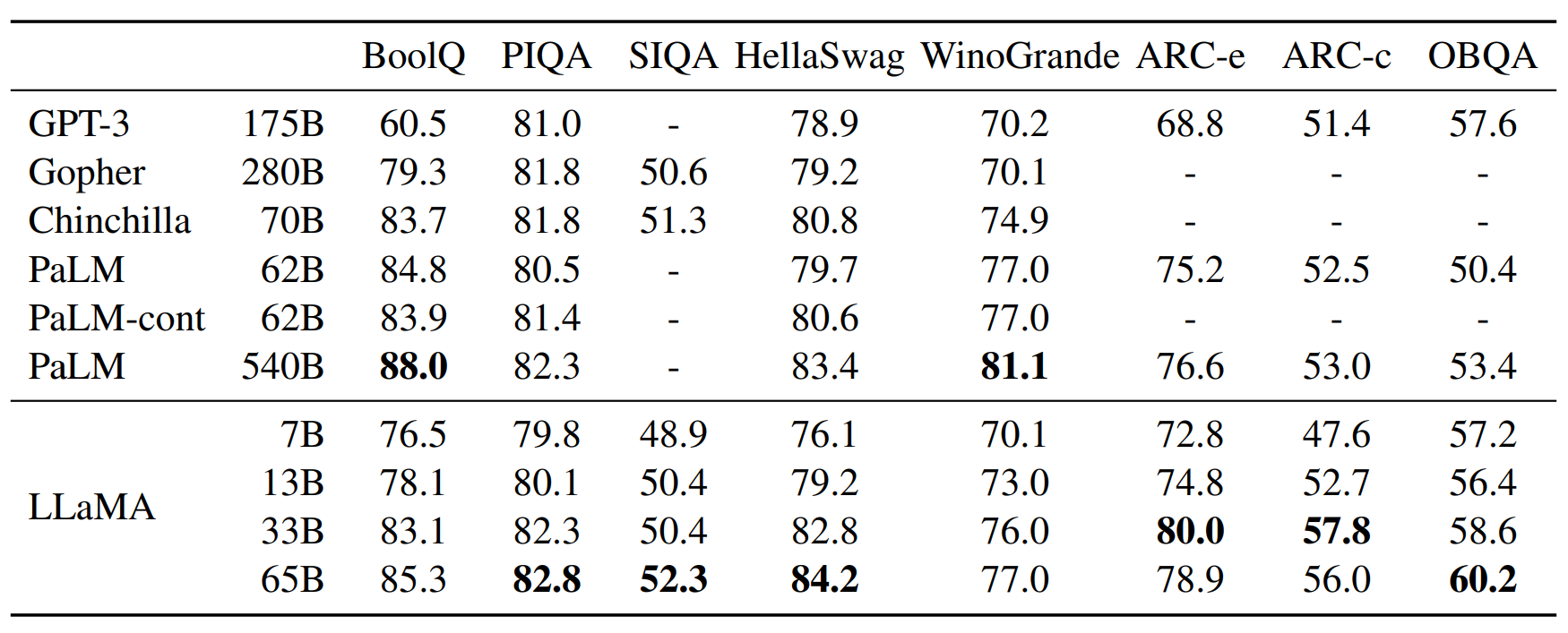
Sens commun
LLaMA-65B s’en tire mieux que Chinchilla-70B sur sept des huit benchmarks. Et mieux que PaLM-540B sur six. LLaMA-13B dépasse GPT-3 et ses 175 milliards de paramètres.
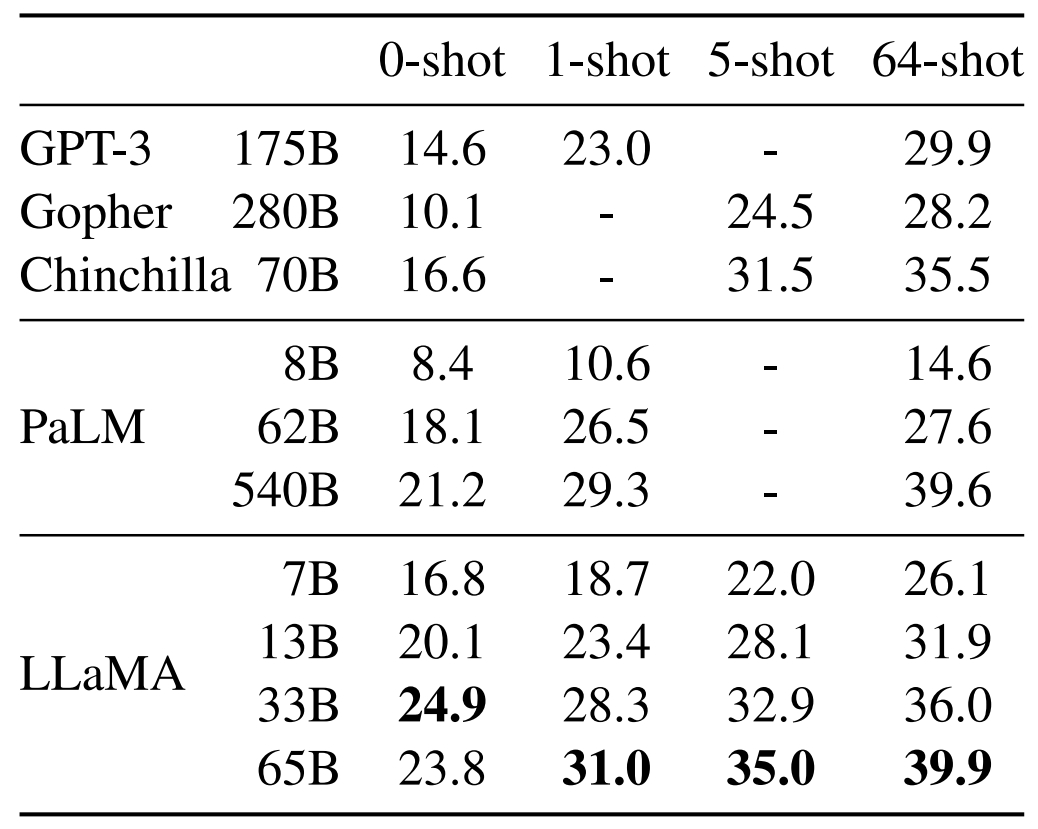
Questions-réponses (benchmarks NaturalQuestions et TriviaQA)
Peu importe le nombre d’exemple qu’on lui fournit, LLaMA s’en tire mieux que la concurrence. La version à 13 milliards de paramètres reste compétitive.
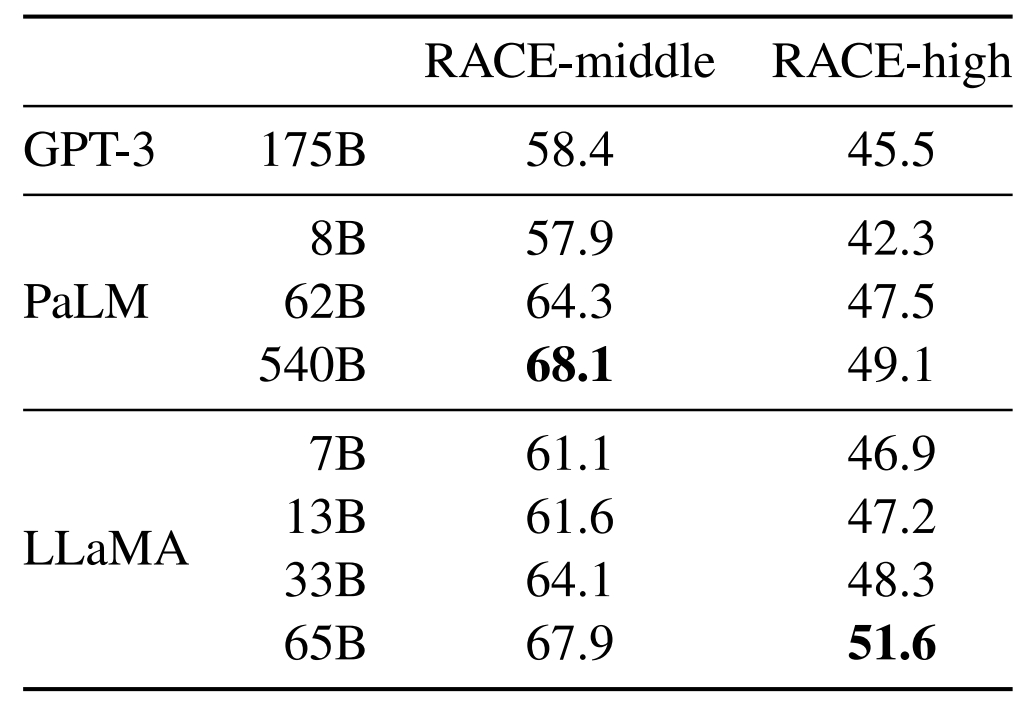
Compréhension écrite
L’évaluation s’est faite sur RACE, un dataset d’examens d’anglais soumis dans des écoles chinoises. LLaMA-65B s’est révélé compétitif face à PaLM-540B (sans toutefois le dépasser) et LLaMA-13B, face à GPT-3.
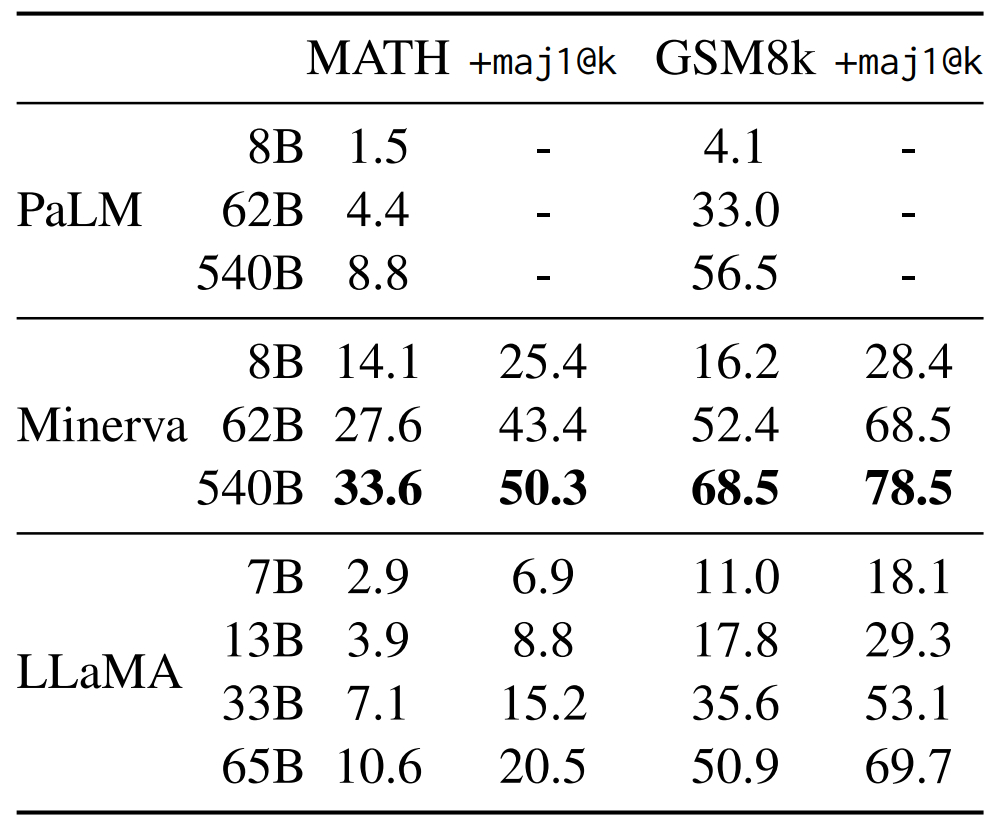
Raisonnement mathématique
Benchmarks scolaires également sur cet exercice. La comparaison s’est faite, d’une part, avec PaLM. De l’autre, avec Minerva, c’est-à-dire une série de modèles PaLM « spécialisés » sur la base d’extraits d’ArXiv et de Math Web Pages.
Le plus puissant des modèles Minerva garde une longueur d’avance. LLaMA-65B dépasse en revanche la version à 62 milliards de paramètres sur GSM8k (problèmes mathématiques niveau collège).
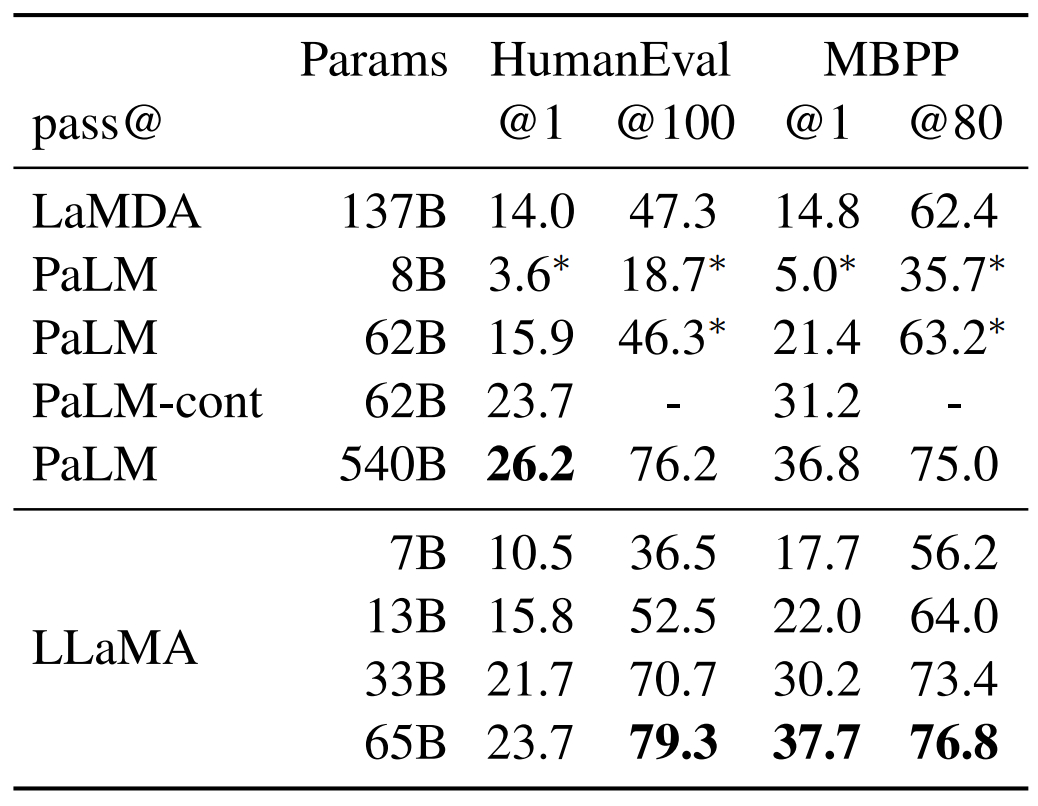
Génération de code
Deux benchmarks « classiques » sont ici exploités : HumanEval et MBPP. À chaque fois, on donne au modèle testé une description en quelques phrases, additionnée d’exemples. Objectif : générer du code Python.
Bilan que tire Meta : à nombre de paramètres similaire, LLaMA fait mieux que les autres (PaLM et LaMDA ayant été entraînés sur un volume comparable de tokens de code).
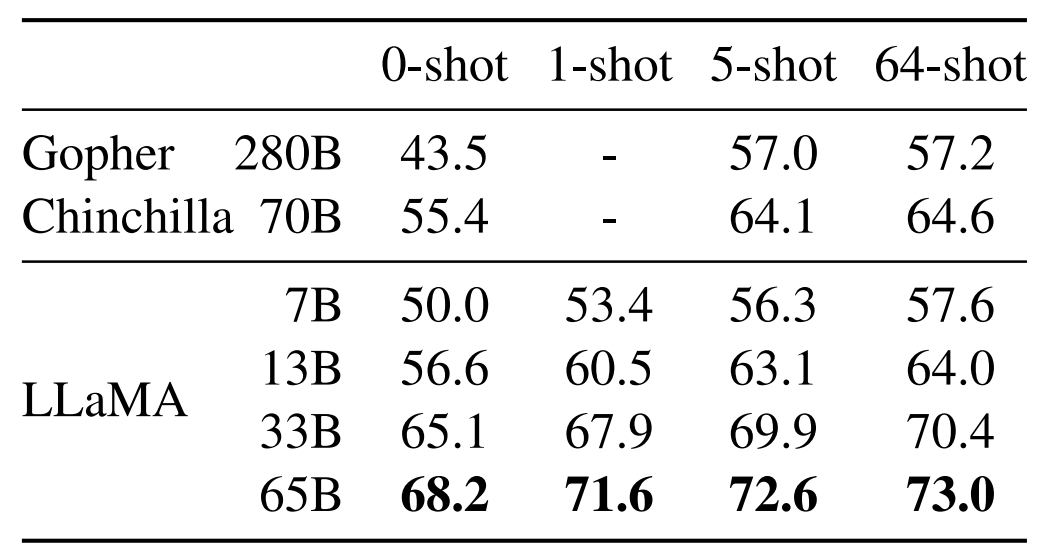
Interprétation massive de langage naturel
Le benchmark ici utilisé est MMLU. Il contient des QCM dans les domaines des sciences humaines, des STEM et des sciences sociales. En 5-shot (5 exemples), LLaMA-65B est derrière Chinchilla-70B et PaLM-540B. Motif, selon Meta : le dataset d’entraînement manque de livres et d’articles académiques (177 Go de données, contre environ 2 To pour les modèles concurrents).
En matière d’éthique, on aura noté les éléments suivants :
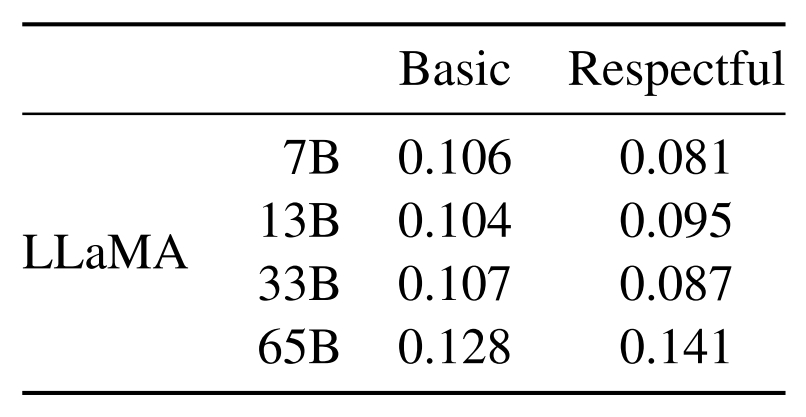
La « toxicité » des modèles LLaMA augmente avec la taille. Ce qui est cohérent avec l’état de l’art dans le domaine des IA génératives.
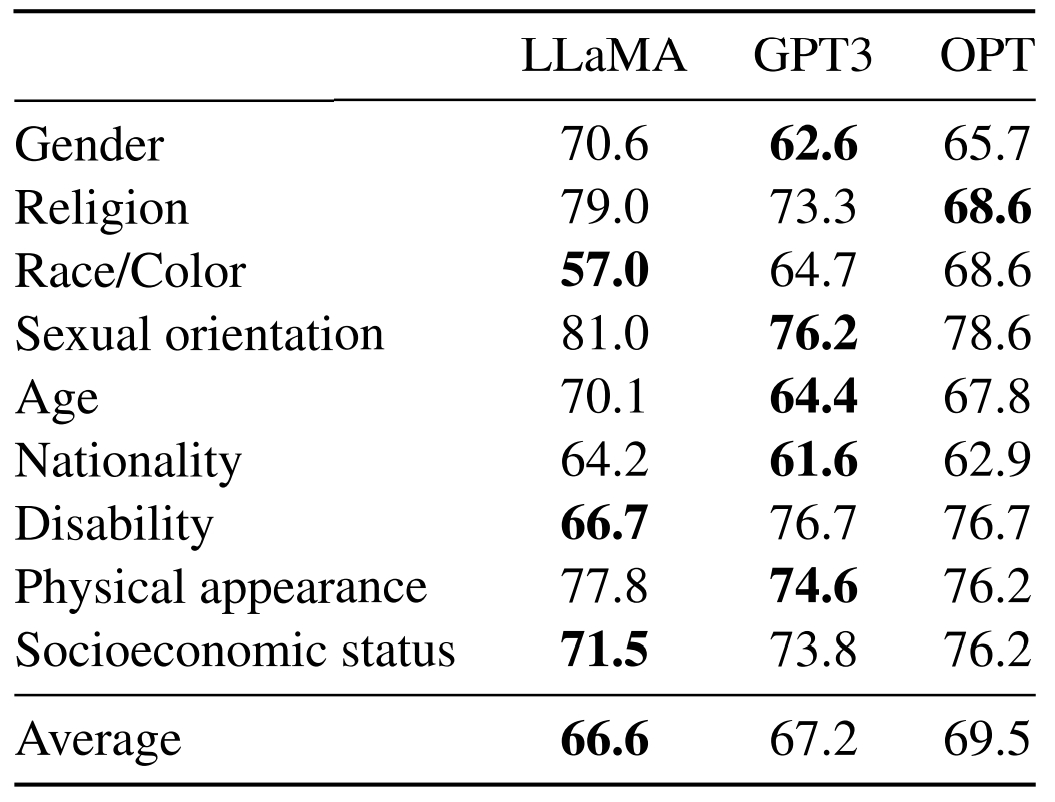
Les stéréotypes de religion sont particulièrement marqués, même si les modèles LLaMA s’en tirent globalement mieux que les autres sur le benchmark CrowS-Pairs. Celui-ci mesure neuf catégories de biais : sexe, race/couleur de peau, orientation sexuelle, handicap, etc.
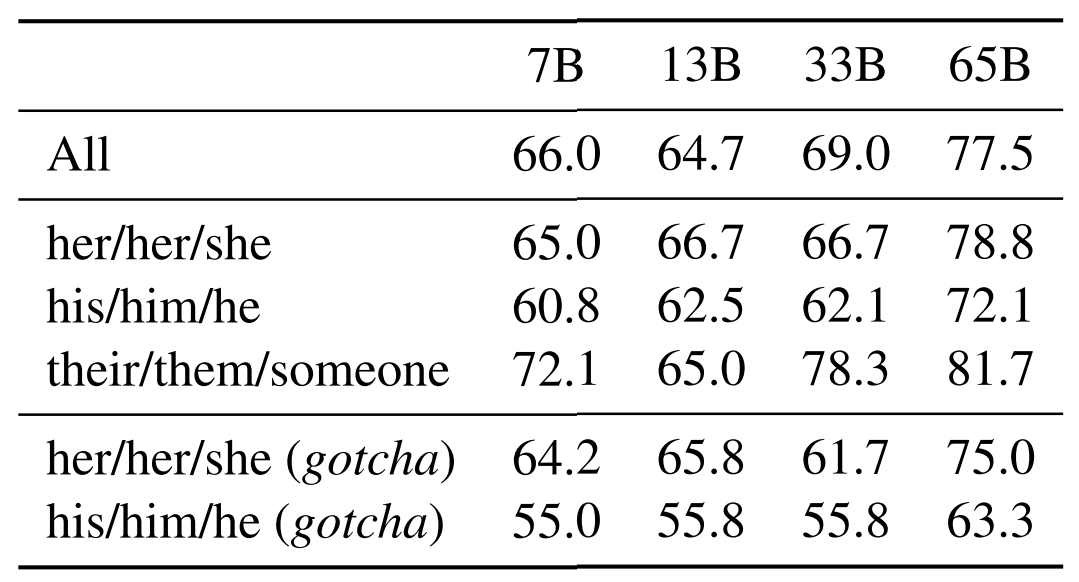
La sensibilité aux biais sociétaux est aussi particulièrement marquée. En tout cas sur la foi du benchmark WinoGender. Celui-ci consiste en des triplets activité-participant-pronom. Les modèles doivent déterminer à quoi se rapporte le pronom. Un exercice moins pertinent dans les langues où le genre est grammaticalement marqué, comme en français. Ce n’est pas le cas en anglais. Témoin la phrase-exemple que donne Meta : « The nurse notified the patient that his shift would be ending in an hour » (« L’infirmière a informé le patient que son quart de travail se terminerait dans une heure. »).
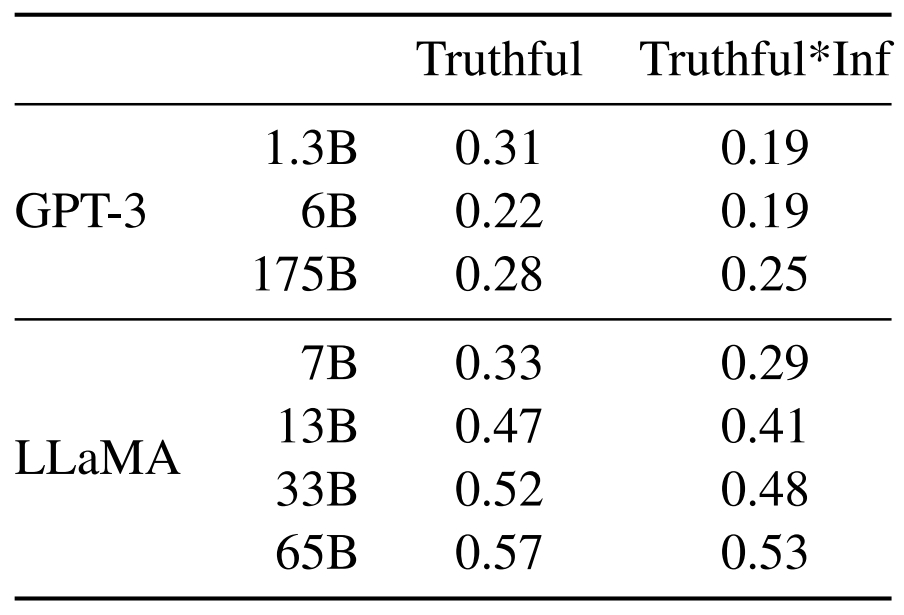
Quant au risque d’halluciner, il reste présent. Même si les performances sont un peu meilleures que celles de GPT-3 sur le benchmark TruthfulQA (évaluation de la véracité de propos), elles restent largement perfectibles.
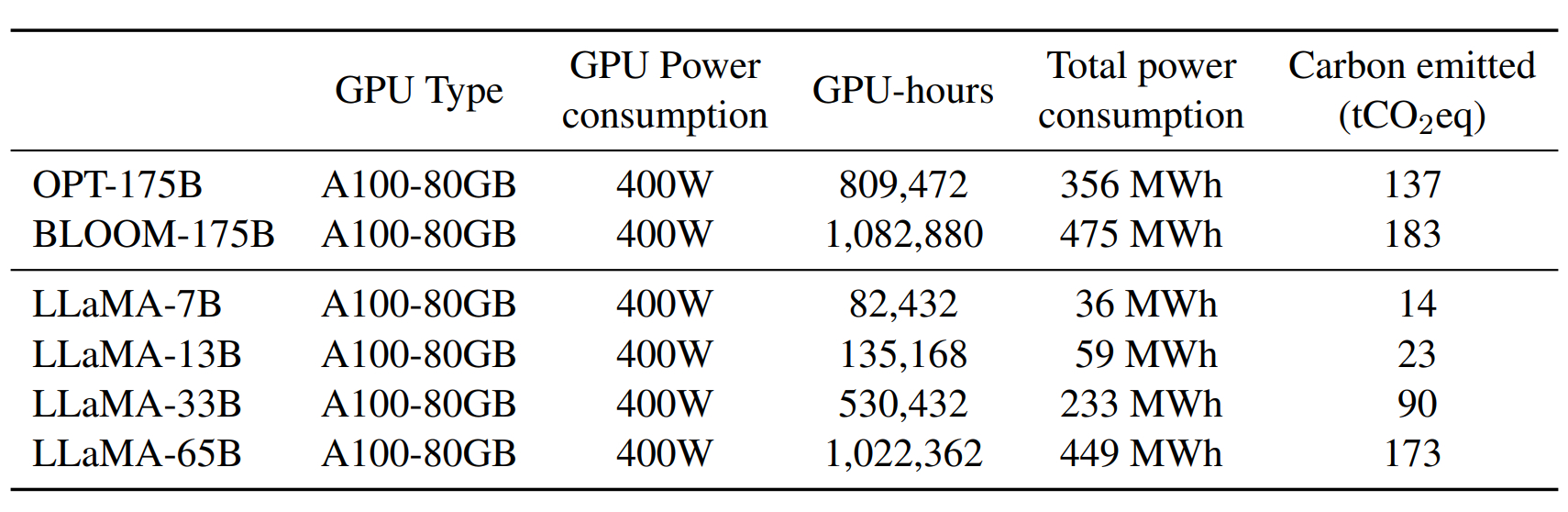
Pour calculer l’empreinte carbone liée à l’entraînement des modèles LLaMA, Meta a suivi une formule établie par Wu et al. Elle implique de retenir un PUE (facteur d’efficacité énergétique des datacenters) fixe, de 1,1. Et d’utiliser, comme facteur d’intensité carbone, la valeur moyenne aux États-Unis (0,385 kg CO2eq/KWh). Pour ce qui est de la consommation des GPU utilisés, on a retenu leur enveloppe thermique (400 W).
Sur la base de ces indicateurs, entraîner LLaMA-65B a requis 449 MWh. Et émis 173 tonnes d’équivalent CO2.
À consulter en complément :
De BigScience à BigCode : la quête d’IA génératives « éthiques »
Hugging Face, faire-valoir d’AWS dans les IA génératives
OpenAI : que peut-on faire avec l’API ?
Illustration principale © AJay – Adobe Stock
La société britannique de cybersécurité Darktrace a accepté une offre de rachat de 5,32 milliards…
Silicon et KPMG lancent la deuxième édition de l'étude Trends of IT. Cette édition 2024…
Le ministère de l'économie a adressé une lettre d'intention à la direction d'Atos pour racheter…
Directeur Technologie de SNCF Connect & Tech, Arnaud Monier lance une campagne de recrutement pour…
Les grands de l'IT suppriment des milliers de jobs au nom du déploiement de. Une…
Quatre ans après l’appel de Rome - un pacte présenté en 2020 par le Vatican…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}