Slurm, Kubernetes ou les deux ? Quel(s) type(s) de stockage pour les checkpoints et les datasets ? Quelle connectivité GPU ? Autant d’aspects que Dell aborde dans son architecture de référence pour l’entraînement de modèles d’IA générative.
Il a décidé d’en rappeler l’existence sous l’angle du « partenariat avec Meta ». Promesse, sur le papier : favoriser le déploiement des modèles Llama 2 sur site (comprendre : sur de l’infrastructure made in Dell).
Le levier : cette architecture de référence… « essentiellement axée sur Llama 2 », pour reprendre les termes du groupe américain. De la présentation des méthodes d’entraînement aux résultats des tests de performance, il n’y a effectivement pas de place pour d’autres modèles. Tout au plus BLOOM, Falcon et MPT sont-ils cités en introduction.
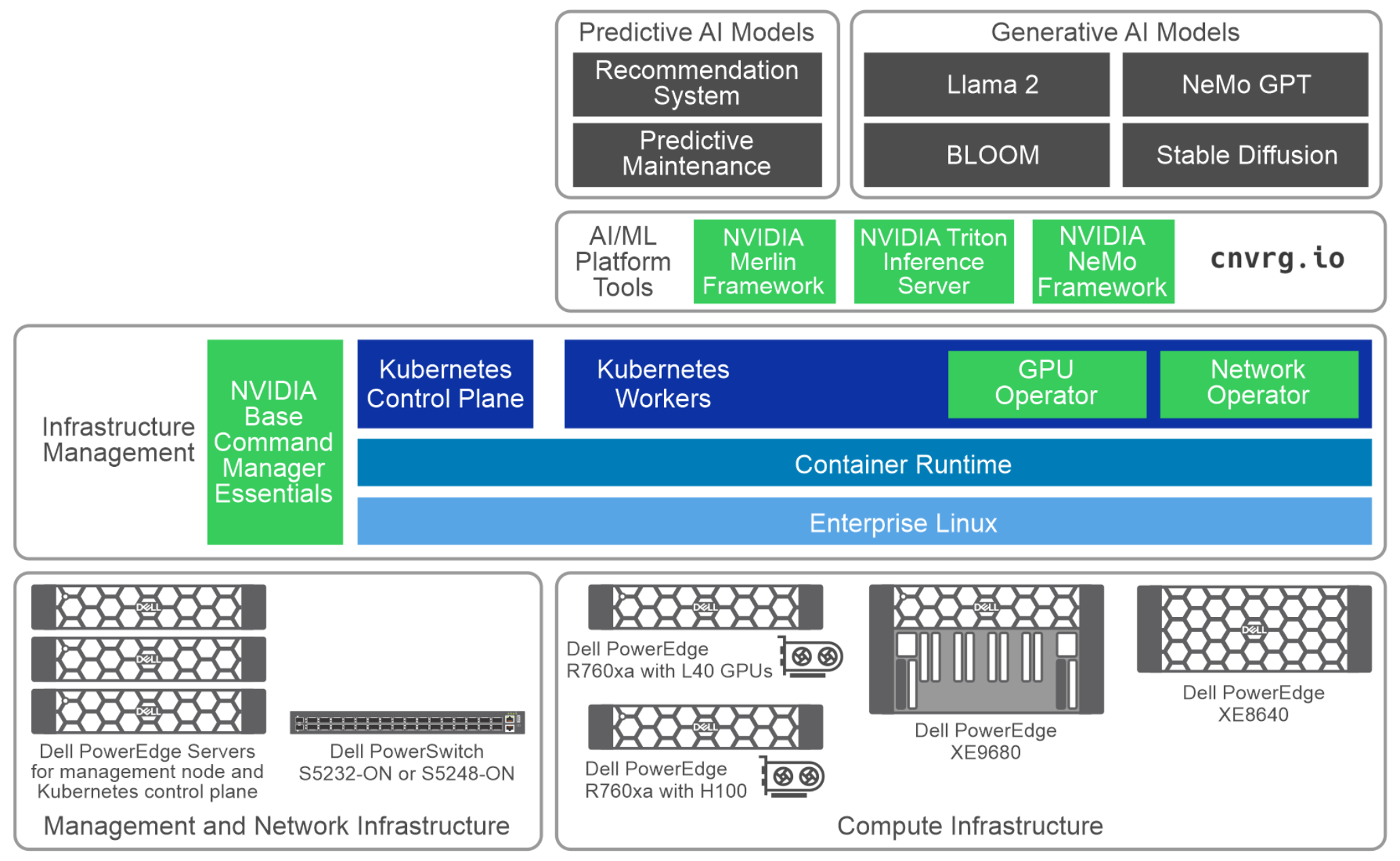
Au niveau hardware, le design suggéré repose, pour la partie compute, sur des serveurs PowerEdge XE9680 à 8 GPU H100-SXM5. Pour la partie stockage, sur des nœuds PowerScale (F600 ou F900). Pour la partie réseau, préférentiellement sur du PowerSwitch Z9432F-ON (100/400 GbE). Le plan de contrôle est sur des serveurs R660.
Au niveau logiciel, il y a plusieurs briques NVIDIA : la plate-forme AI Enterprise, la plate-forme AI Enteprise avec le framework NeMo, le serveur d’inférence Triton et l’orchestrateur Base Command Manager Essentials. Dell y associe ses outils de gestion OpenManage Enterprise, Power Manager et CloudIQ.
L’architecture réseau physique se présente comme suit. Le gestion, le stockage et le trafic nord-sud se font sur Ethernet. InfiniBand – en configuration HDR ou NDR – gère la connectivité est-ouest.
Dell dispose aussi d’une architecture de référence pour l’inférence. Elle exploite des serveurs PowerEdge R760xa (en A100 ou H100). Pour le stockage, c’est du PowerScale, de l’ECS et/ou de l’ObjectScale. Et pour le réseau, du PowerSwitch S5232F-ON (25/100 Gb) ou S5248F-ON (25 Gb).
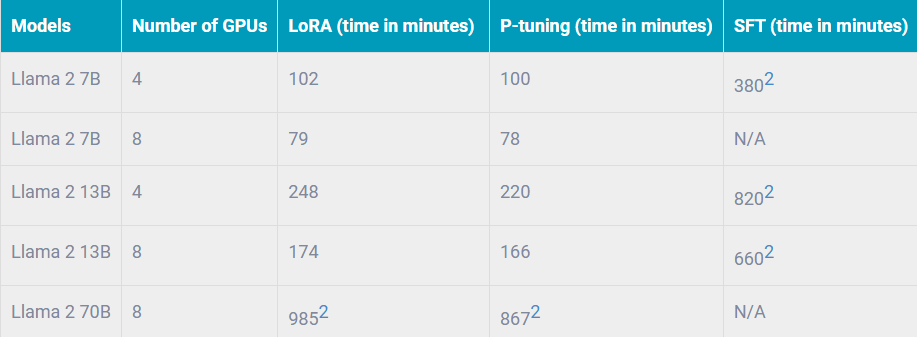
Pour valider son design en entraînement, Dell a testé les méthodes de réglage fin supervisé (SFT), d’optimisation de prompts (p-tuning) et d’adaptation à faible rang (LoRA). Ses jeux de données de référence : Dolly (origine Databricks) et Alpaca (Stanford). Le tableau suivant présente les résultats sur le premier avec un nœud PowerEdge XE9680.
Illustration principale © AJay – Adobe Stock
Comment gérer les données numériques après la mort de son détenteur ? La jeune pousse…
Ivès, expert en accessibilité de la surdité, s’est associé à Sopra Steria et à IBM…
L'Autorité de la concurrence et des marchés (CMA) a lancé la phase de recherche de…
Broadcom remplace pas moins de 168 logiciels VMware par deux grandes licences de location correspondant…
La banque d’investissement utilise l'IA pour proposer des stratégies individualisées, en termes de rendement et…
OVHCloud partage ses efforts environnementaux au sommet de l’Open Compute Project qui se tient à…
{kind=link}
{kind=link}