Quel est le principal atout de l’humain par rapport à l’intelligence artificielle ? Le sens commun. En tout cas pour ce qui est de produire des énoncés plausibles. C’est le principal enseignement d’une expérience qu’ont menée des chercheurs basés aux États-Unis.
Leur constat n’a rien de nouveau. Leur méthodologie ouvre néanmoins des pistes susceptibles de favoriser l’acquisition dudit sens commun par les modèles d’apprentissage automatique.
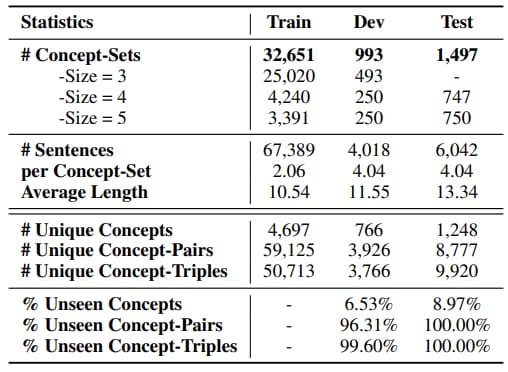
L’expérience a consisté à mettre à l’épreuve une dizaine de ces modèles. Le but : générer des propos cohérents pour décrire des scénarios du quotidien. On les a pour cela entraînés à partir d’un corpus de 77 499 phrases dont on a tiré 35 141 « concepts » (noms ou verbes).
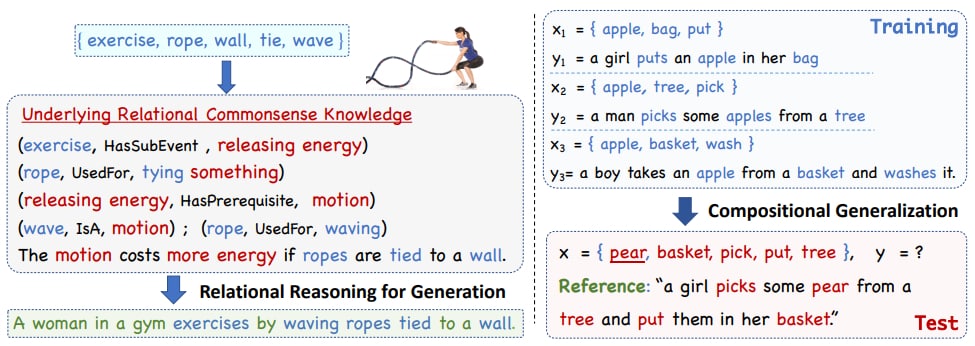
Remplir l’objectif recherché suppose deux capacités. D’un côté, savoir saisir les relations entre concepts. De l’autre, pouvoir « généraliser » ; c’est-à-dire aborder des notions ou des combinaisons de notions jamais vues auparavant.
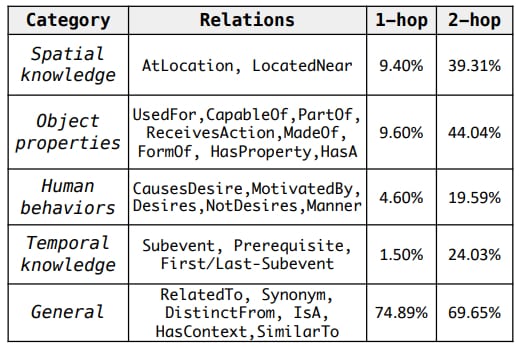
Ces deux aspects nous sont si évidents qu’on les intègre rarement dans les données qui servent à entraîner les modèles d’IA. Cela se ressent d’autant plus, expliquent les chercheurs, qu’on enchaîne les associations de concepts pour aller vers des scénarios. En la matière, le plus important semble la capacité à interpréter les propriétés des objets et les relations spatiales.
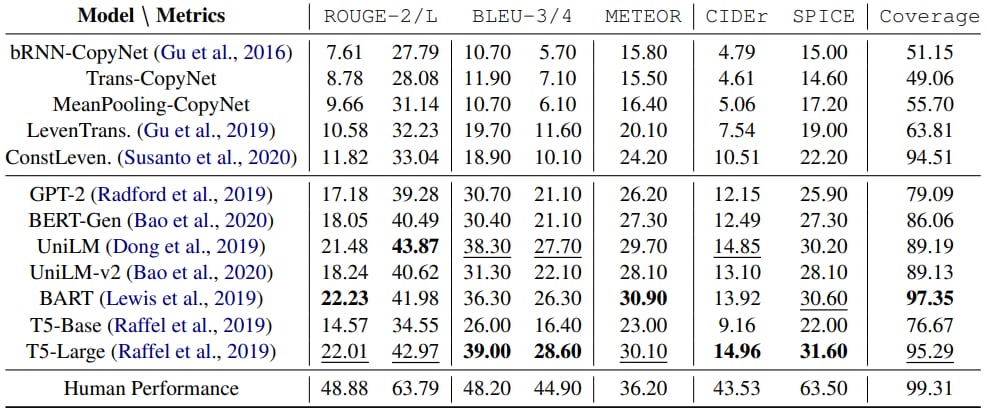
L’ensemble des modèles mis à l’épreuve ont fait l’objet d’un entraînement préalable avec ConceptNet (base de connaissances du sens commun). Ceux déjà formés en amont sur des tâches relatives à l’interprétation du langage naturel s’en tirent mieux, comme l’illustre le tableau ci-dessous.
Leurs performances restent toutefois sans comparaison avec celle de l’humain. BART, par exemple, a la meilleure couverture conceptuelle, mais a tendance à faire des répétitions. Quant à T5, il a tendance à oublier les agents.
Au-delà de cette expérience, l’entraînement qu’ont subi les différents modèles les a rendu plus performants pour d’autres tâches. En premier lieu, la réponse aux questions en langage naturel.
Illustration principale © lassedesignen – Fotolia
Un temps pressenti pour constituer le socle d'une suite bureautique AWS, Amazon WorkDocs arrivera en…
Eviden regroupe cinq familles de serveurs sous la marque BullSequana AI. Et affiche le supercalculateur…
Le dernier Magic Quadrant du SSE (Secure Service Edge) dénote des tarifications et des modèles…
Formats de paramètres, méthodes d'apprentissage, mutualisation GPU... Voici quelques-unes des recommandations de l'ANSSI sur l'IA…
À la grogne des partenaires VMware, Broadcom répond par diverses concessions.
iPadOS a une position suffisamment influente pour être soumis au DMA, estime la Commission européenne.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}