crédit photo © Peshkova - shutterstock
Annoncée il y a trois semaines lors de l’événement Ignite, la nouvelle mouture de la base de données de Microsoft, SQL Server 2016, est désormais disponible dans sa première version publique, dénommée Community Technology Preview (CTP2). La base de données est, au fil des ans, devenue un produit clef dans la stratégie de Microsoft. Comme l’expliquait Damien Cudel, chef de marché plate-forme applicative chez Microsoft France dans un entretien avec la rédaction il y a quelques semaines, il s’agit là de la quatrième ligne de revenus du premier éditeur mondial depuis quelques années. « Et le produit qui a le plus contribué à la croissance de Microsoft ces trois dernières années », selon lui. SQL Server représente un chiffre d’affaires annuel de plus de 6 milliards de dollars pour l’éditeur.
Selon Damien Cudel, l’investissement de Microsoft dans ce produit se concentre sur trois priorités : renforcer les fonctions permettant de supporter les applications critiques, fournir des capacités clef en main d’exploitation de la donnée et exploiter les capacités de croissance des volumes qu’offre le Cloud. Les principales nouveautés de SQL Server 2016 illustrent bien la priorité donnée à ces trois axes de développement.
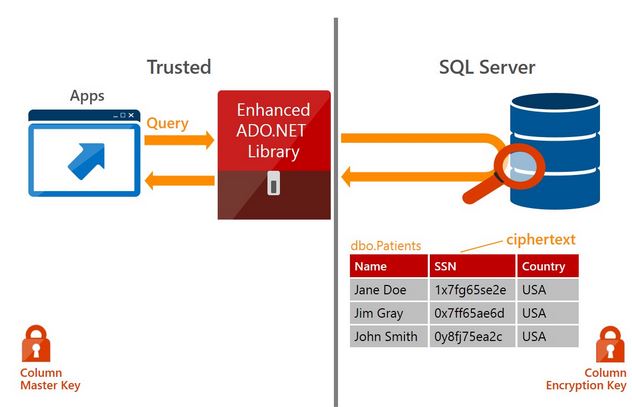
Du côté des fonctions analytiques, Microsoft intègre le langage de programmation R, en vogue auprès des statisticiens (Lire « Analytique Big Data : R sera intégré en standard au sein de SQL Server 2016 ») ainsi que PolyBase, outil « qui permet de faire la jonction entre le monde SQL et le monde Hadoop », assure Damien Cudel. Surtout, Microsoft insiste sur le rapprochement entre ses technologies In-Memory OLTP (transactionnel) et son entrepôt de gestion des index en colonnes et en mémoire (analytique). Si cette intégration s’inscrit bien dans la continuité des versions précédentes (notamment de la version 2014), elle ouvre la voie à des applications analytiques temps réel au sein de SQL Server 2016, notamment en faisant disparaître les processus ETL. L’approche rappelle celle de SAP Hana, qui en plaçant toutes les données en mémoire permet de fusionner applications transactionnelles et analytiques. « Mais l’approche de SAP est de type tout ou rien. Au sein de SQL Server, on peut se contenter de placer les 2 ou 3 tables les plus sollicitées en mémoire. On dégage alors 90 % des gains qu’aurait amenés un transfert total en mémoire pour un investissement modéré en infrastructures », résume Damien Cudel.
A lire aussi :
Damien Cudel, Microsoft : « Faciliter les prototypes Big Data… puis leur industrialisation »
5 questions pour comprendre la guerre Oracle – SAP dans le In-Memory
Un temps pressenti pour constituer le socle d'une suite bureautique AWS, Amazon WorkDocs arrivera en…
Eviden regroupe cinq familles de serveurs sous la marque BullSequana AI. Et affiche le supercalculateur…
Le dernier Magic Quadrant du SSE (Secure Service Edge) dénote des tarifications et des modèles…
Formats de paramètres, méthodes d'apprentissage, mutualisation GPU... Voici quelques-unes des recommandations de l'ANSSI sur l'IA…
À la grogne des partenaires VMware, Broadcom répond par diverses concessions.
iPadOS a une position suffisamment influente pour être soumis au DMA, estime la Commission européenne.
{kind=link}
{kind=link}