Quel point commun entre l’orchestrateur de microservices Conductor, le planificateur de tâches Dagobah, le format de données Iceberg, la bibliothèque de data science Metaflow et le gestionnaire de conteneurs Titus ? Toutes ces briques, aujourd’hui open source, émanent de Netflix.
La plate-forme américaine les a notamment mises à contribution pour construire une infrastructure de machine learning dédiée aux contenus multimédias. Elle est revenue dernièrement sur ces travaux, en mettant l’accent sur le passage à l’échelle. Pour un cas d’usage en particulier : la détection des séquences qui se prêtent le mieux au match cut (technique de transition entre deux scènes utilisant la même composition, le même cadrage, la même action…).
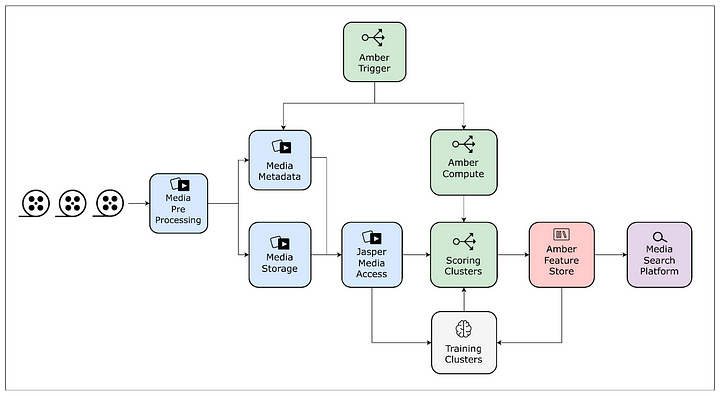
Dans un premier temps, l’infrastructure a été mise en œuvre à périmètre limité. En l’occurrence, un seul film ou épisode de série. Le pipeline était découpé en cinq étapes :
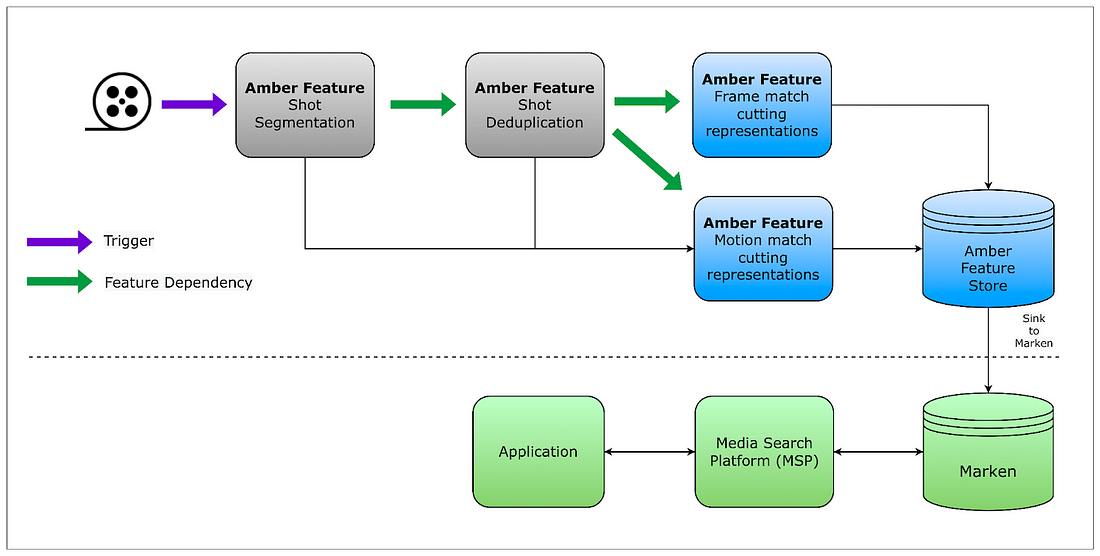
Dans chaque fichier, délimiter les scènes par un système clé-valeur (numéro de la scène – numéros des images de début et de fin). Puis créer autant de fichiers individuels.
> Vectoriser chacun de ces fichiers et utiliser les vecteurs pour supprimer les doublons.
> Vectoriser à nouveau chaque scène, mais selon le type de match cut souhaité.
> Attribuer un score à chaque paire de scènes et stocker ces scores au niveau des métadonnées.
> Trier les paires par score décroissant et sélectionner les k meilleures (k étant un paramètre personnalisable).
Lorsqu’il s’agit de traiter plusieurs films/épisodes en parallèle et/ou d’utiliser plusieurs variantes de match cut, les choses se compliquent. D’abord parce que les vectorisations sont sensibles aux caractéristiques des fichiers – comme le format d’encodage et les dimensions. En réponse, Netflix a appliqué un prétraitement de son catalogue pour livrer des copies « normalisées ». Il fournit une bibliothèque unifiée pour y accéder : Jasper.
Autre enjeu : réduire les ressources de calcul nécessaires pour qui vient exécuter ses modèles de machine learning sur ce catalogue. Netflix a développé un cluster GPU à l’appui du framework Ray et lui a associé le système de fichiers objet MezzFS pour optimiser les chargements. Il a surtout mis en place un magasin de données dans une logique de mutualisation. Il y héberge, par exemple, les paires clé-valeur correspondant à la segmentation des scènes. L’idée : éviter à chacun de les recalculer. Le tout est équipé d’un système de réplication vers diverses solutions de stockage.
Sur la partie orchestration, le chantier a impliqué le développement d’une solution « universelle » capable de déclencher l’exécution des modèles de prod dès la mise à disposition de nouveaux contenus. Le manque de standardisation a là aussi été un obstacle : les opérations étaient parfois relancées alors que seules les métadonnées liées à ces contenus avaient changé. La compatibilité n’était par ailleurs pas native avec des orchestrateurs comme Conductor.
Le magasin de données est connecté à un autre outil origine Netflix : le service d’annotation Marken. Il fait l’interface avec les applications – typiquement, les éditeurs vidéo – avec un langage de requête spécifique.
Illustration principale © Ismail Rajo – Adobe Stock
Formats de paramètres, méthodes d'apprentissage, mutualisation GPU... Voici quelques-unes des recommandations de l'ANSSI sur l'IA…
À la grogne des partenaires VMware, Broadcom répond par diverses concessions.
iPadOS a une position suffisamment influente pour être soumis au DMA, estime la Commission européenne.
FT Group, éditeur du Financal Times, a signé un accord avec OpenAI afin d'utiliser ses…
Au premier trimestre, Microsoft, Meta/Facebook et Alphabet/Google ont déjà investi plus de 32 milliards $…
La société britannique de cybersécurité Darktrace a accepté une offre de rachat de 5,32 milliards…
{kind=link}
{kind=link}