Sécuriser une IA, ce n’est pas simplement éviter qu’elle échappe au contrôle humain. Ce sont aussi des choses plus prosaïques* allant du contrôle des accès à la gestion des privilèges.
NVIDIA a récemment émis une forme de rappel à ce sujet, en évoquant sa « red team IA » et le cadre méthodologique dans lequel elle évolue.
Ledit cadre s’applique à l’évaluation de tout système impliquant de l’apprentissage automatique. Aussi bien, donc, un serveur de modèles qu’un lac de données d’entraînement ou une application décisionnelle. Il ne préconise pas de processus, mais aide à les organiser autour de quelques paradigmes.
L’approche est segmentée de sorte qu’on peut associer les outils et services analysés aux différentes phases du cycle de vie des systèmes concernés. Elle a, affirme NVIDIA, l’avantage de poser des « frontières naturelles » de sécurité, facilitant par exemple le tiering des privilèges.
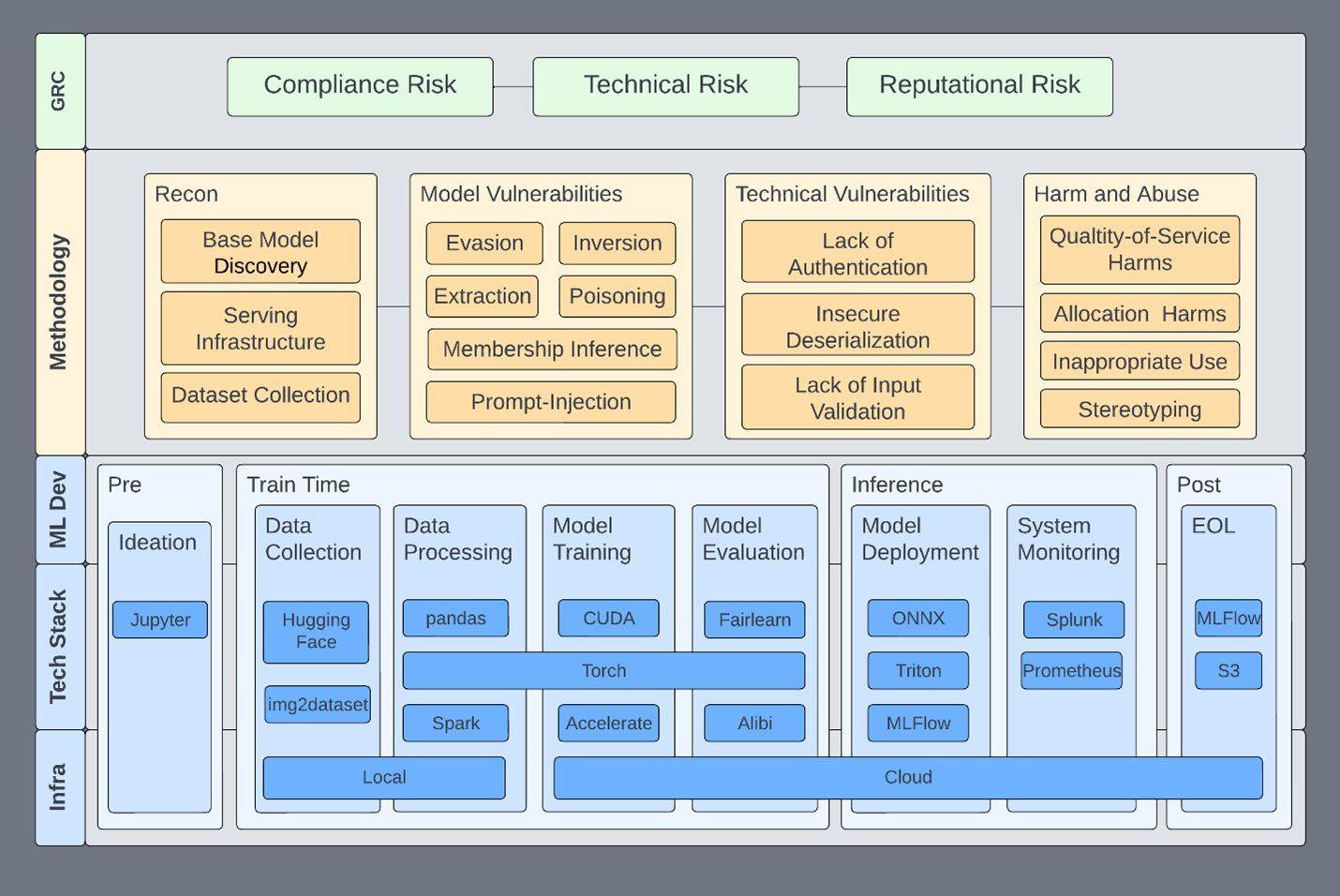
Au sommet de la pyramide, il y a le triptyque classique entre les risques liés à la conformité, à la technologie et à la réputation. La méthodologie se décline ensuite sur quatre aspects :
– Reconnaissance (découverte des modèles, infrastructure et collecte de données)
– Vulnérabilités des modèles (« empoisonnement », injection de prompts, extraction d’éléments…)
– Vulnérabilités techniques (authentification, désérialisation, validation des entrées)
– Usages abusifs ou indésirables
Cette segmentation permet, par exemple, de traiter les vulnérabilités techniques dans le contexte de la fonctionnalité concernée. Ou d’inclure des TTP (techniques, tactiques et procédures) pertinentes pour évaluer un certain type de modèle. L’intégration des usages abusifs ou indésirables motive par ailleurs les équipes techniques à les prendre en considération.
* Au rang des « choses prosaïques », NVIDIA mentionne aussi :
– Un serveur Flask hébergeant un modèle destiné à traiter des données sensibles… déployé avec les privilèges de débogage et exposé à Internet
– Des données personnelles intégrées dans un jeu de données d’entraînement
– Un bucket contenant des modèles de prod… et laissé en accès public
– Quelqu’un qui parvient systématiquement à contourner les filtres de modération
– Un modèle qui ne fonctionne pas comme attendu dans certaines régions géographiques
À consulter en complément :
S3 : AWS veut en finir avec les accès publics
Cybersécurité : 8 outils open source pour évaluer sa surface d’attaque
PoisonGPT : des LLM détournés à la racine
IA et données publiques : Google joue carte sur table
NVIDIA s’affirme en boussole des IA génératives
Illustration principale © EwaStudio – Adobe Stock
Formats de paramètres, méthodes d'apprentissage, mutualisation GPU... Voici quelques-unes des recommandations de l'ANSSI sur l'IA…
À la grogne des partenaires VMware, Broadcom répond par diverses concessions.
iPadOS a une position suffisamment influente pour être soumis au DMA, estime la Commission européenne.
FT Group, éditeur du Financal Times, a signé un accord avec OpenAI afin d'utiliser ses…
Au premier trimestre, Microsoft, Meta/Facebook et Alphabet/Google ont déjà investi plus de 32 milliards $…
La société britannique de cybersécurité Darktrace a accepté une offre de rachat de 5,32 milliards…
{kind=link}