


Le Cloud règne en maître sur la « Modern Data Stack ». Les plateformes big data sont désormais exclusivement dans le Cloud et cette évolution s’amplifie encore avec l’apparition de solution « tout en un », uniquement disponible en SaaS.
En quelques années, le Cloud a totalement bousculé la façon dont les entreprises stockent et exploitent leurs données. Exit les grands « Data Warehouse » et leurs baies de stockage spécialisées, exit les architectures big data basées sur des racks de serveurs Hadoop.
Non seulement les entrepôts de données ont pris le chemin du Cloud, mais c’est aussi le cas de toutes les briques logicielles satellites comme les ETL / ELT, les solutions de streaming de données et tout le volet Dataviz et IA.
Désormais, une architecture big data ne se conçoit plus que dans le Cloud : c’est la « Modern Data Stack » (MDS), une gestion moderne des données.
L’essor de ce modèle a fait le succès de solutions comme Snowflake, Databrick, et bien évidemment les services de data lake managés des hyperscalers : BigQuery de Google en tête et RedShift chez AWS.
Modern Data Stack : le choix de Databricks
Bachar Wehbi, Solution Architect chez Databricks argumente en faveur de cette approche :
« Notre solution Lakehouse offre une plateforme unifiée multi-cloud, avec une data stockée en format ouvert pour éviter tout lock-in, une couche unifiée transversale de gouvernance et de sécurité pour les données. »
Pour Databricks, les différents profils amenés à travailler les données dans l’entreprise doivent collaborer ensemble sur sa plateforme pour implémenter des cas d’usage allant de l’informatique décisionnelle (« Business Intelligence ») à l’intelligence artificielle. Il ajoute : « La valeur apportée par le Lakehouse est d’accélérer l’innovation, tout en réduisant les coûts. »
L’éditeur pousse fort le développement de son offre vers MLOps et l’arrivée des IA génératives, le fameux mouvement GenAI. On lui doit la publication en open source de MLflow, mais aussi le LLM (« Large Language Models ») Dolly en 2023.
Avec l’acquisition de MosaicML en juin 2023, Databricks a ajouté à son offre une solution optimisée pour l’entraînement et le réglage fin (« Fine Tuning ») des LLM et grands modèles d’IA.
Depuis 2021-2022, ce modèle Cloud s’est clairement imposé, mais il pose un certain nombre de problèmes propres au modèle « As a Service ». Car si les plateformes ont souvent démarré modestement, les volumes de données se sont accrus et les cas d’usage de la data se multipliant, on leur a connecté de plus en plus de sources de données. Cette croissance de type scale up et scale out est venue mécaniquement augmenter le coût des plateformes et de chacun des outils périphériques.
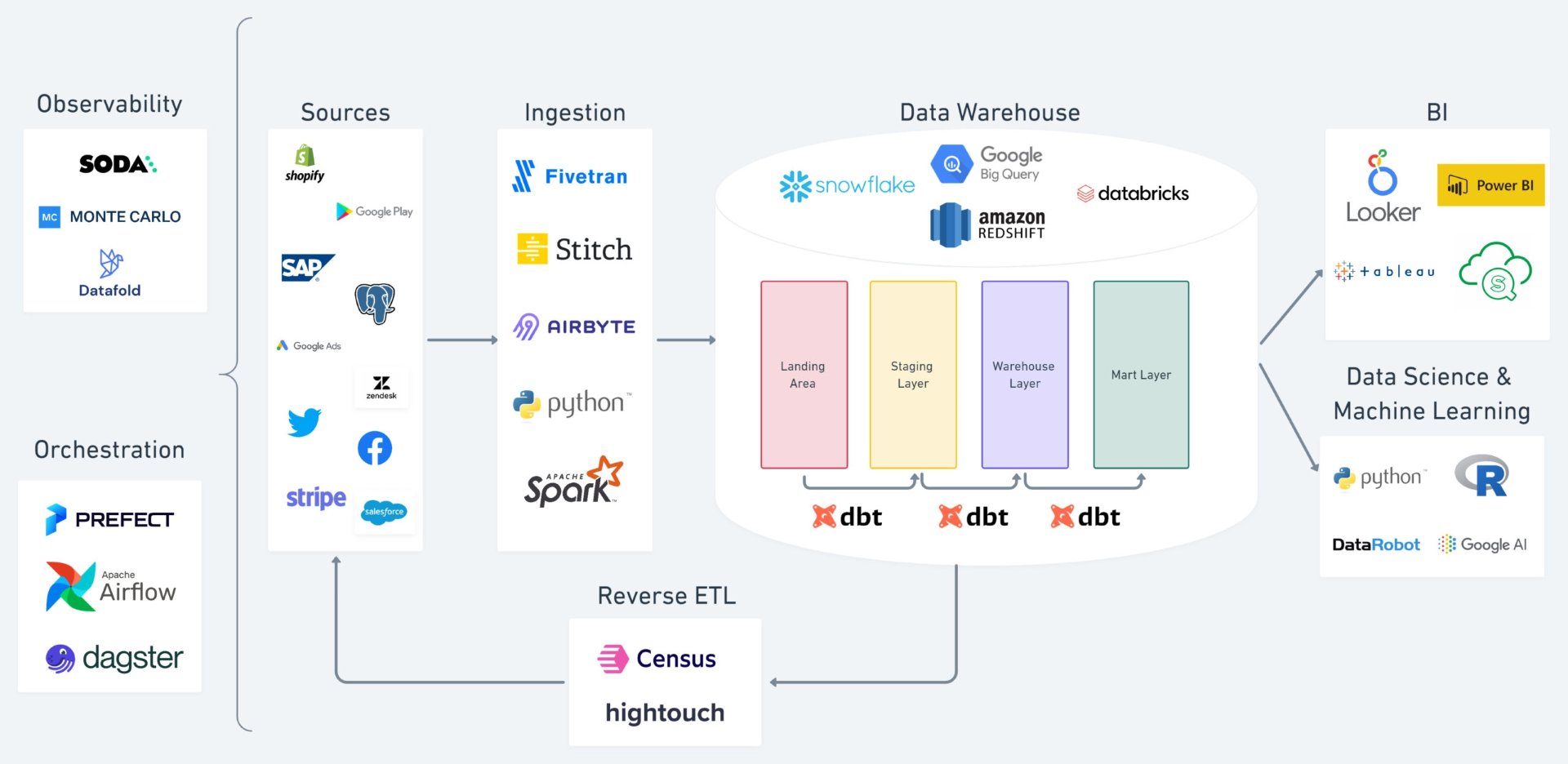
Outre l’aspect financier, la modern data stack pose clairement la question de la gestion de la complexité dans la durée. L’empilement de solutions complémentaires et la multitude de briques open source nécessaires entraîne des surcoûts liés à leur intégration. Il faut pouvoir s’appuyer en interne sur des ingénieurs de haut vol, à la fois coûteux et… volatiles.
Le modèle MDS montre ses limites
Ariel Pohoryles, Head of Product Marketing chez Rivery, start-up israélienne qui édite un service managé d’intégration de données mise en œuvre par Blablacar, estime qu’une nouvelle génération de plateformes va succéder au MDS. « La modern data platform reprend les mêmes principes, mais sous forme d’un environnement unifié qui permet un contrôle de bout en bout du pipeline, depuis l’ingestion, la transformation, de l’orchestration et le reverse ETL. »
Le responsable évoque une interface commune pour l’ensemble des fonctionnalités de la plateforme et délivre une vue globale favorable à une meilleure observabilité sur les données et les processus. « Nous sommes parvenus à consolider le nombre d’outils, mais aussi celui des rôles nécessaires pour créer des solutions de bout en bout. Avec une plateforme unifiée qui offre une interface utilisateur consistante, les utilisateurs qui ne travaillaient que sur la transformation des données et laissaient l’ingestion aux data engineers peuvent désormais créer eux-mêmes les pipelines d’ingestion des données. »
Dans le même esprit, l’éditeur allemand Software AG ( récemment racheté par IBM) a bâti une offre au-dessus de Snowflake pour faciliter l’import et la transformation des données. Selon l’éditeur, la solution doit raccourcir le cycle d’analyse des données et bénéficier d’une interface graphique qui va simplifier l’utilisation de la MDS par les équipes.
Jean-Marc Le Gonidec, Architect Solution chez Software AG argumente : « La solution Transformer for Snowflake » offre une interface graphique intuitive et des composants de transformation prêts à l’emploi. La solution permet d’implémenter les transformations complexes supportées par Snowflake de manière simple et rapide, tout en limitant les modifications en cas de changements sur les données brutes. Cela vient renforcer l’approche libre-service, ainsi que faciliter la collaboration entre data scientists, data engineers, data analysts, ou encore les analytic engineers.»
Le moteur d’intégration de Software AG, le Data Collector peut être déployé sur site, ou en mode hybride à proximité des sources de données ou d’un broker de message comme Kafka.
Microsoft dévoile sa Microsoft Fabric
Autre éditeur majeur de l’informatique d’entreprise à prendre position sur la modern data platform, Microsoft.
Outre ses nombreuses offres dédiées au monde du big data, notamment Azure Data Lake Storage, HDInsight et Azure Data Factory, l’éditeur vient de dévoiler Microsoft Fabric.
« La motivation principale derrière Microsoft Fabric, c’est la simplicité de la data platform afin de passer plus de temps à travailler avec les données, que de gérer des intégrations entre les produits» résume Soulaima Ben Rejeb, Cloud Solution Architect Data et AI chez Microsoft.
« Pour arriver à cette simplification, nous nous sommes appuyés sur trois piliers : d’une part une architecture de type lake house centrée sur OneLake, un format open source, pour faciliter l’accès à la donnée. Deuxièmement, le choix du modèle SaaS comme pour PowerBI afin de simplifier l’expérience utilisateur. Enfin, le troisième pilier, c’est augmenter la productivité des utilisateurs métiers ou techniques comme les data engineer et data scientists en intégrant l’IA Copilot à tous les niveaux. »
Microsoft mise donc sur Fabric pour contrer les offres de type MDP et répondre aux attentes des entreprises qui cherchent une approche plus unifiée de leur data. Microsoft Fabric intègre les fonctions de data integration, data engineering, data warehouse, data science, real time analytics, business intelligence et observabilité sur une fondation unifiée, un stockage unifié, OneLake.
Dans une instance OneLake unique, l’entreprise va pouvoir créer des workspaces comparables à ceux de PowerBI, une logique qui reprend celle des datamarts d’antan.
