

Big Data et Cloud : Splunk étend son emprise sur les SI

Créée en 2004 et bénéficiaire dès 2009, Splunk compte déjà 8400 clients dans le monde. Zoom sur ce logiciel Big Data qui a évolué des données machine, aux applications, au développement, à la sécurité puis à la mobilité.

L’avènement du Big Data a fait naître des solutions capables non seulement d’examiner des gros volumes de données, mais aussi de corréler des informations dans tous les formats possibles, plus ou moins à pas du tout structurés.
Or justement, les serveurs, les réseaux, Internet, les périphériques clients (mobiles ou non) et autres appareils électroniques du système d’information ne cessent de générer de milliers d’informations dans de multiples formats : disponibilités, données machines, géolocalisation, adresses réseau et/ou IP, informations protocolaires, états applicatifs, informations utilisateur, parcours Web… Logique donc que de nombreux produits s’intéressent à ces informations vitales.
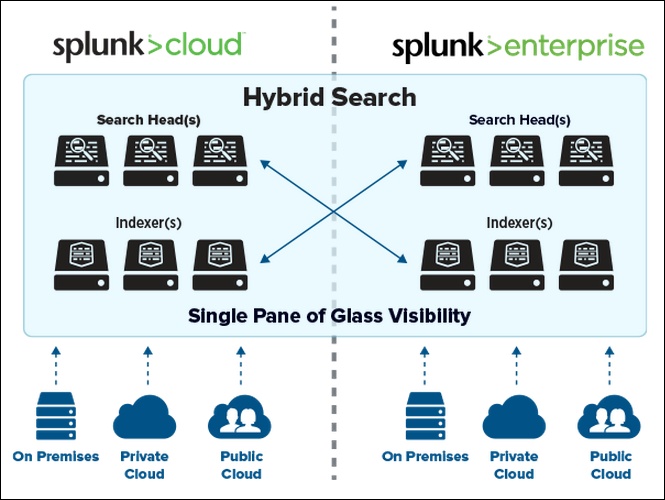
Moins de 10 ans pour devenir le phare des SI d’entreprises
Créé en 2004 par Rob Das et Erik Swan, l’éditeur de logiciel Splunk a commercialisé sa solution éponyme en 2006. Splunk Enterprise collecte, indexe et exploite à la volée toutes les données machine d’une infrastructure informatique (environnements physiques, virtuels ou cloud) pour obtenir une visibilité globale et temps réel des ressources opérationnelles. Tous ces logs (générés par les systèmes, le matériel ou les logiciels) sont également corrélés avec les flux réseau. Cet ensemble peut ensuite donner lieu à la génération automatique d’alertes ou de rapports.
« Le principe de départ était de rendre les données machine accessibles, exploitables et utiles pour tous,» scande Pierre Goyeneix, directeur de la zone EMEA Sud chez Splunk. «Jusqu’en 2010 environ, l’approche des données non structurées consistait à imposer un schéma à l’écriture pour les intégrer à une base de données relationnelle à interroger en SQL. Depuis, une autre approche prédomine : considérer les informations dans leur ensemble et les indexer au fil de l’eau de façon universelle, afin de pouvoir les rechercher en créant un schéma à la volée lors de la lecture.» Outre la version logicielle, le service Splunk Cloud est disponible également en Europe, depuis quelques semaines.
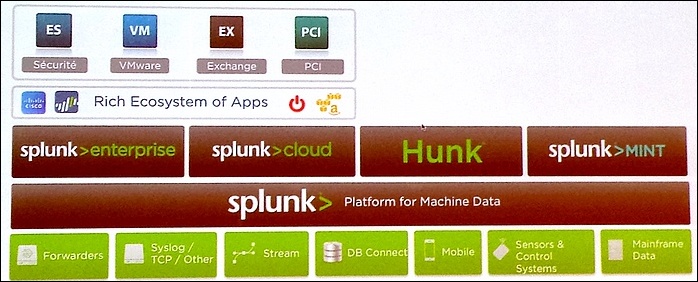
Intelligence opérationnelle à tous les étages
Supervision des machines et des applications du système d’information (y compris les services Cloud), Splunk va au-delà de la supervision de l’infrastructure.
Ainsi, le tracking de code de bout en bout et le suivi des versions peuvent épauler les développeurs pour optimiser et pour déployer ses applications. Côté sécurité, les comportements anormaux et les menaces sont repérés et surveillés en continu avec mise en évidence des éléments apparemment à l’origine des problèmes. L’éditeur affirme aller fonctionnellement au-delà des solutions SIEM (Security information and event management) traditionnelles.
La société propose évidemment des modules pour gérer le respect des règles de conformité à l’échelle de l’entreprise; et des extensions pour Microsoft Exchange, Active Directory ou Windows.
Depuis le rachat de BugSense en septembre 2013, Splunk propose (versions Express et Entreprise) eux développeurs d’applications mobiles d’optimiser et superviser leurs réalisations via le service cloud MINT Express. Par ailleurs Splunk MINT Enterprise (encore en version beta) sait combiner les données des environnements mobiles avec celles de la plateforme Splunk (logiciel, cloud ou hybride). La vision pour l’Internet des Objets semble aller de soi.
Enfin, sa solution Hunk permet de connecter Splunk directement sur un Data Lake Hadoop pour l’interroger et générer rapports, alertes, et toute la panoplie du logiciel.

Sous le capot : genre Hadoop… mais non !
Pour réaliser sa solution, l’éditeur n’a pas réalisé une implémentation d’Hadoop ou de HDFS (système de fichiers distribué Hadoop), mais il a conçu son propre système de gestion de fichiers distribué et son propre moteur d’exécution en cluster. Une approche qui ressemblerait presque à Hadoop, mais avec certaines caractéristiques différenciatrices dès le départ.
«Aujourd’hui, il est encore soit impossible, soit très difficile et onéreux de faire du temps réel avec Hadoop,» souligne Pierre Goyeneix. «Or, les entreprises ne souhaitent pas avoir à attendre plusieurs secondes pour interroger un CRM afin de connaître un taux de transformation, par exemple.»
La solution peut être utilisée à plusieurs niveaux. Son langage de type “script structuré” SPL (Search Processing Language) s’adresse plutôt aux développeurs et administrateurs de bases de données pour réaliser leurs recherches. Un langage non compilé qui favorise un paramétrage très évolutif, et la création de modèles réutilisables par des utilisateurs non informaticiens.
Depuis la version 6, une fonction Instant Pivot s’adresse aux utilisateurs non informaticiens (mais un peu initiés). Il repose sur des métadonnées (autodétectées et/ou générées en SPL) utilisées en simple glisser-déposer pour réaliser des rapports dont l’utilisateur choisit l’apparence parmi les multiples graphiques afin de composer ses tableaux de bord.
Dans a dernière version, l’éditeur a introduit des fonctions de machine learning via lesquels Splunk découvre automatiquement des patterns (modèles) afin de révéler des décalages ou anomalies, tendances, phénomènes répétitifs, etc. Au vu des multiples données et corrélations, cela met en évidence des phénomènes difficiles ou impossibles à détecter autrement.
Mobilité, Internet des objets, machine learning, temps réel… Splunk intègre rapidement toutes les technologies de pointe à sa plateforme. En outre, l’éditeur multiplie les domaines d’application. Positionné stratégiquement au cœur de tous les flux de données pour leur donner du sens, et avec une architecture distribuée et évolutive : où s’arrêtera-t-il ?
A lire aussi :
Auchan ajoute du Big Data à la sauce Splunk à son panier e-Commerce
Silicon Valley Tour – Apporter de la visibilité dans le capharnaüm applicatif






