

Big Data : Teradata embrasse Hadoop… faute de pouvoir l’éviter

Le spécialiste du datawarehouse Teradata approfondit ses relations avec l’écosystème Hadoop. Et ce même si le framework Open Source permet, sur le papier, de faire baisser le coût global de ses solutions.
Ne pas rester la tête dans le sable face à la modification profonde des systèmes de gestion de données, marquée par la montée en puissance des bases NoSQL et du framework Hadoop. C’est en somme le message qu’a tenu à confirmer Teradata, acteur historique des grands datawarehouse d’entreprise, lors de son événement européen Universe (Amsterdam, du 20 au 22 avril). Pour Chris Twogood, le vice-président marketing de l’éditeur américain, « les entreprises font face à plusieurs défis : tirer parti des données disponibles, fournir des réponses aux attentes de leurs utilisateurs et réduire les coûts et la complexité des environnements IT actuels ». Un dernier domaine dans lequel les technologies Open Source ont évidemment des arguments à faire valoir.
Plutôt que de tenter de résister à la montée en puissance des Hadoop, MongoDB, Cassandra ou autre, Teradata tente de la digérer. « Nous sommes passés du datawarehouse traditionnel au datawarehouse logique, combinant nos architectures à de nouveaux systèmes de gestion de données », résume Chris Twogood. Quitte à ouvrir la porte à des architectures qui peuvent se révéler concurrentes sur une partie du périmètre que couvrent les solutions maison. « Chaque jour, nous sommes en concurrence avec un fournisseur qui peut aussi devenir un partenaire demain », justifie Hermann Wimmer, le co-président de Teradata (en photo ci-dessus).
QueryGrid : une requête, de multiples sources
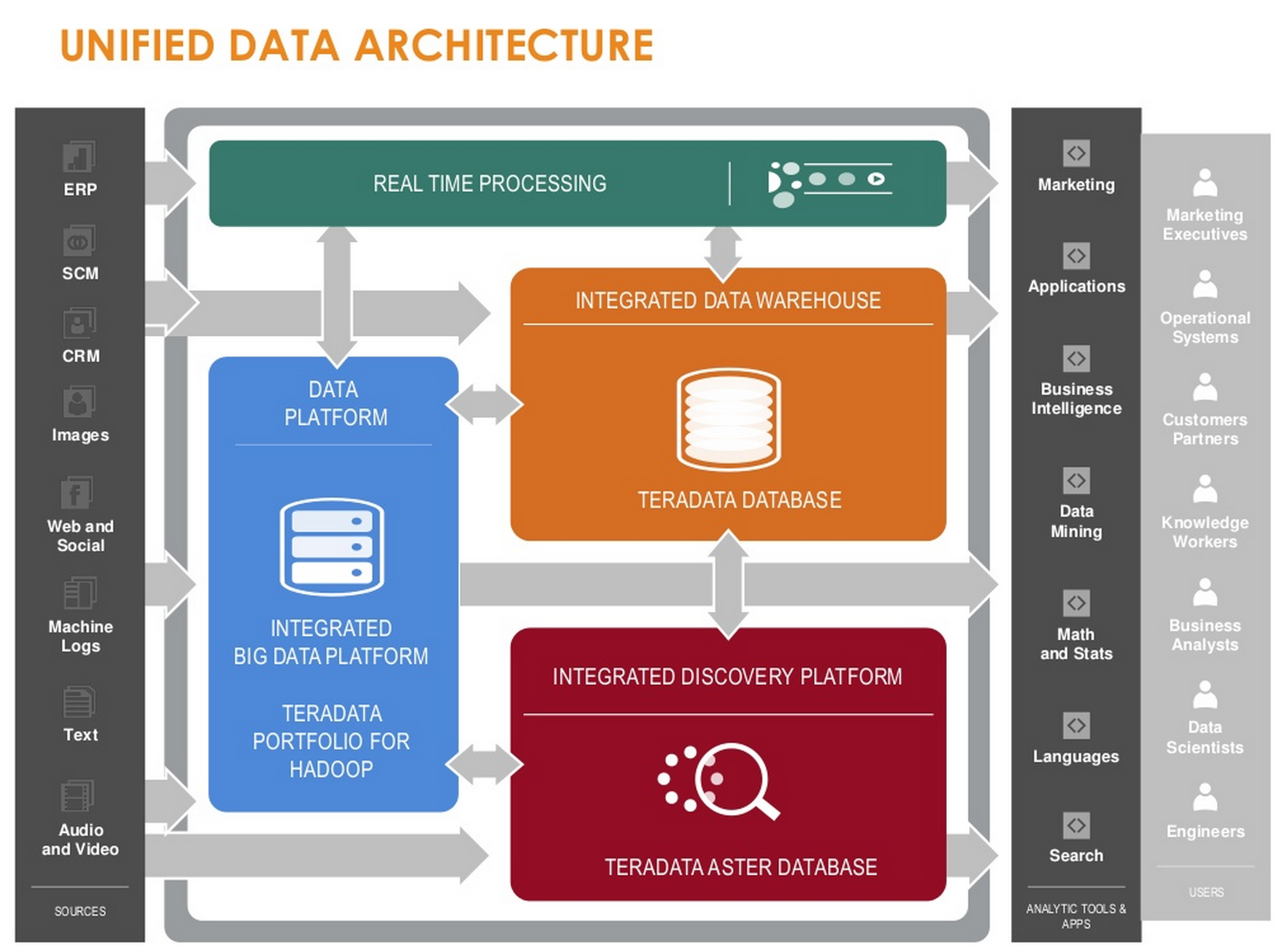 Cette stratégie s’est matérialisée par le lancement, il y a deux ans, de Unified Data Architecture (schéma ci-contre). Une architecture où l’on retrouve, autour des datawarehouse maison, les technologies Big Data, un outil de découverte (Aster, issu d’un rachat en 2011) et un moteur de requêtes unifié, QueryGrid, permettant d’interroger de multiples sources de données. « Le développement de cette solution part du constat que de nombreuses technologies ont besoin d’être orchestrées, détaille Stephen Brobst, le directeur technique de l’éditeur. QueryGrid permet l’exécution des requêtes en langage natif, des connecteurs assurant la translation vers les technologies où résident les données. L’outil assure ensuite la consolidation des réponses. » Les nouveautés dévoilées lors de ce cru 2015 de Universe ne font d’ailleurs que confirmer les orientations stratégiques de Teradata : intégration de la distribution Hadoop MapR et des dernières versions de Cloudera et Hortonworks dans QueryGrid, apparition d’une version multitenant de la technologie maison permettant à une entreprise de consolider plusieurs datawarehouse sur une unique appliance (donc de réduire les coûts) ou encore internationalisation annoncée de Think Big Analytics, une société de services spécialisée dans l’intégration des technologies Open Source de Big Data que Teradata a rachetée en septembre dernier.
Cette stratégie s’est matérialisée par le lancement, il y a deux ans, de Unified Data Architecture (schéma ci-contre). Une architecture où l’on retrouve, autour des datawarehouse maison, les technologies Big Data, un outil de découverte (Aster, issu d’un rachat en 2011) et un moteur de requêtes unifié, QueryGrid, permettant d’interroger de multiples sources de données. « Le développement de cette solution part du constat que de nombreuses technologies ont besoin d’être orchestrées, détaille Stephen Brobst, le directeur technique de l’éditeur. QueryGrid permet l’exécution des requêtes en langage natif, des connecteurs assurant la translation vers les technologies où résident les données. L’outil assure ensuite la consolidation des réponses. » Les nouveautés dévoilées lors de ce cru 2015 de Universe ne font d’ailleurs que confirmer les orientations stratégiques de Teradata : intégration de la distribution Hadoop MapR et des dernières versions de Cloudera et Hortonworks dans QueryGrid, apparition d’une version multitenant de la technologie maison permettant à une entreprise de consolider plusieurs datawarehouse sur une unique appliance (donc de réduire les coûts) ou encore internationalisation annoncée de Think Big Analytics, une société de services spécialisée dans l’intégration des technologies Open Source de Big Data que Teradata a rachetée en septembre dernier.
Présents en masse sur l’événement organisé par Teradata, les éditeurs de distribution Hadoop détaillent les scénarios d’usage combinant les datawarehouse de l’Américain et le framework Open Source. « Le cas que l’on rencontre le plus souvent consiste à utiliser Hadoop pour décharger l’ETL associé au datawarehouse traditionnel. Les entreprises utilisent alors Hadoop pour stocker des données anciennes ou des données brutes avant leur transformation par l’ETL. Les utilisateurs acceptent des accès plus lents mais au bénéfice d’une équation économique bien plus rationnelle », détaille Nicolas Maillard, ingénieur solutions chez Hortonworks. « Utiliser Hadoop pour sa capacité à monter en charge présente beaucoup d’intérêt, ajoute Rob Anderson, le vice-président en charge de l’ingénierie de MapR Technologies. Vous pouvez l’employer pour faire ‘atterrir’ vos données, de formats variés, non structurées ou très volumineuses, afin de les nettoyer, les analyser, les enrichir ou les structurer. Vous pouvez aussi l’utiliser comme outil de pré-transformation de la donnée. Ou encore comme stockage permanent, à un niveau de coût très intéressant ». Contrairement à Teradata, qui repose sur des appliances coûteuses, Hadoop fonctionne sur des infrastructures standard. « L’idée centrale consiste à réserver le datawarehouse aux fonctions pour lesquelles il est le plus adapté : la gestion des accès concurrents, l’accès aux données ayant la valeur la plus importante… », détaille un porte-parole sur le stand de Cloudera.
Hadoop pour décharger Teradata
« Utiliser des cycles machine Teradata pour préparer de la donnée n’a que peu de sens économiquement, reprend Nicolas Maillard. Or, 30 % de la puissance des appliances Teradata est souvent employé par l’ETL, alors que cette ressource pourrait être utilisée par des tâches apportant de la valeur ajoutée aux métiers. » Selon lui, l’approche consistant à exploiter Hadoop pour décharger les infrastructures Teradata aurait beaucoup de succès en France. Hortonworks affirme y compter une vingtaine de clients travaillant sur ces sujets. Si l’approche est évidemment bénéfique pour les budgets des DSI, elle se traduit immédiatement par une baisse des besoins en appliances et licences Teradata. « Est-ce que cette démarche prend des parts de marché à Teradata ? On pourrait répondre par l’affirmative, mais uniquement si on ne tient pas compte du contexte, qui voit le volume de données croître rapidement et les entreprises chercher à se rapprocher de leurs clients, reprend l’ingénieur de Hontonworks. Dans de nombreux secteurs, faire baisser le churn (taux de départ de clients, NDLR) de 2 % masque un enjeu économique énorme. »
Stephen Brobst, le directeur technique de Teradata, ne dit d’ailleurs pas autre chose : « sur le terrain, les entreprises utilisent en réalité Hadoop pour amener dans le datawarehouse des données qu’elles auraient auparavant jetées ». Spécialiste du secteur de la distribution chez l’éditeur – un des points forts historiques de Teradata et un secteur très sensible aux moindres optimisations économiques -, Katarine Hansson assure que les entreprises de la distribution qui ont opéré les virages les plus radicaux vers le framework Open Source en reviennent. « Hadoop facilite davantage les usages de nos technologies qu’il ne les concurrence », dit-elle.
Il n’en reste pas moins que les résultats financiers de l’éditeur d’Atlanta (Géorgie) semblent plafonner, malgré les rachats réalisés par le fournisseur. En février dernier, Teradata annonçait pour l’année dernière un chiffre d’affaires de 2,73 milliards de dollars, en progression de 3 % sur un an à taux de change constant, avec des marges en léger recul. La société s’attend à une croissance similaire en 2015.
A lire aussi :
Stephen Brobst, Teradata : « nous assisterons à la disparition du Big Data par l’intégration »
Big Data : comment SoLocal apprivoise Hadoop
Big Data : ça avance… mais en ordre dispersé






